scAdam model optimization#
Model optimization refers to the process of improving the performance and efficiency of machine learning models. scAdam models support two types of optimization:
Warm start: Warm starting is a technique in machine learning that involves initializing a model with weights from a previously trained model on the same or a similar task. This method allows the training process to begin from a more advantageous point on the loss surface, leveraging prior knowledge to improve efficiency and performance.
Hyperparameter tuning: This involves adjusting the hyperparameters of the model, such as learning rates, batch sizes, and other configuration settings, to optimize performance on a specific dataset.
[1]:
# Python packages
import warnings
warnings.simplefilter('ignore')
import scanpy as sc
import scparadise
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
sc.set_figure_params(dpi = 120)
Recommendations about training dataset#
We recommend shifted logarithm data normalization method:
sc.pp.normalize_total(adata, target_sum=None)
sc.pp.log1p(adata)
But you can use any other method of data normalzation (Use the same normalization method for test dataset)
Training dataset sould contain all genes that you want to use for model training in adata_train.X We recommend to remove all non-marker genes from adata_train.X (removeing of such useless genes may increase performance and model quality metrics and also increase training speed)
Data preparation#
Here we download and preprocess dataset from cellxgene:
Single cell RNA sequencing of oropharyngeal squamous cell carcinoma https://cellxgene.cziscience.com/collections/3c34e6f1-6827-47dd-8e19-9edcd461893f
[2]:
# Download data from figshare
# You can use wget, or download the file in a browser by copying and pasting the link into a new tab.
link = 'https://datasets.cellxgene.cziscience.com/5ee8e8dd-6f0e-4336-aec8-f476b0b0089b.h5ad'
[3]:
# Load prepared for training anndata object
adata = sc.read_h5ad('5ee8e8dd-6f0e-4336-aec8-f476b0b0089b.h5ad')
[4]:
# Get raw counts from adata.raw
adata = adata.raw.to_adata()
[5]:
# Convert var_names from ENSG codes to gene names
adata.var.set_index('feature_name', inplace=True)
adata.var_names = adata.var_names.astype('str')
adata.var_names_make_unique()
[6]:
# Select datasets for model training and testing
# It is necessary for all cell types to be present in both the training datasets and the testing datasets
df = scparadise.scnoah.cell_counter(adata, celltype='cell_type', sample='donor_id')
df
[6]:
| HN481 | HN482 | HN483 | HN485 | HN487 | HN488 | HN489 | HN490 | HN492 | HN494 | |
|---|---|---|---|---|---|---|---|---|---|---|
| epithelial cell | 6747 | 758 | 934 | 575 | 2061 | 1335 | 2533 | 2955 | 2619 | 780 |
| plasma cell | 868 | 1051 | 498 | 609 | 106 | 596 | 1005 | 975 | 642 | 579 |
| CD8-positive, alpha-beta T cell | 613 | 1129 | 1204 | 740 | 279 | 941 | 1004 | 472 | 1408 | 911 |
| fibroblast | 512 | 164 | 256 | 163 | 371 | 118 | 856 | 204 | 234 | 560 |
| myeloid cell | 415 | 311 | 159 | 361 | 995 | 136 | 929 | 394 | 203 | 2998 |
| regulatory T cell | 370 | 316 | 623 | 351 | 135 | 69 | 881 | 385 | 321 | 616 |
| endothelial cell | 283 | 174 | 144 | 111 | 122 | 152 | 311 | 240 | 135 | 138 |
| CD4-positive, alpha-beta T cell | 282 | 1272 | 2629 | 911 | 87 | 224 | 1310 | 1076 | 789 | 1784 |
| mural cell | 267 | 170 | 98 | 156 | 195 | 173 | 286 | 233 | 87 | 128 |
| B cell | 213 | 1837 | 3369 | 764 | 30 | 2053 | 1338 | 2297 | 942 | 1832 |
| mast cell | 92 | 56 | 91 | 56 | 20 | 39 | 33 | 29 | 74 | 27 |
| natural killer cell | 88 | 135 | 205 | 65 | 40 | 120 | 465 | 94 | 58 | 128 |
| mature alpha-beta T cell | 44 | 31 | 13 | 7 | 8 | 7 | 82 | 30 | 38 | 42 |
| endothelial cell of lymphatic vessel | 29 | 23 | 25 | 10 | 8 | 9 | 59 | 6 | 28 | 8 |
| plasmacytoid dendritic cell | 19 | 31 | 43 | 25 | 13 | 22 | 87 | 24 | 20 | 163 |
[7]:
# Create adata_train1, adata_train2 and adata_test datasets
adata_test = adata[adata.obs['donor_id'].isin(['HN481', 'HN482'])].copy()
adata_train_1 = adata[adata.obs['donor_id'].isin(['HN483' 'HN485', 'HN488', 'HN489'])].copy()
adata_train_2 = adata[adata.obs['donor_id'].isin(['HN490', 'HN487', 'HN492', 'HN494'])].copy()
del adata
[8]:
# Normalize data, find highly variable features
for i in [adata_train_1, adata_train_2, adata_test]:
i.layers['counts'] = i.X.copy()
sc.pp.normalize_total(i, target_sum=None)
sc.pp.log1p(i)
[9]:
# Find highly variable features for scAdam model training
sc.pp.highly_variable_genes(
adata_train_1,
layer='counts',
flavor='seurat_v3',
n_top_genes=1200,
subset=True
)
Default model training#
Use ‘balanced_accuracy’ as the evaluation metric in this case due to the imbalance in the number of cells among cell types.
[10]:
# Train scadam model using adata_train1 dataset
scparadise.scadam.train(
adata_train_1,
path='', # path to save model
model_name='model_scadam', # folder name with model
celltype_keys=['cell_type'],
eval_metric=['accuracy', 'balanced_accuracy']
)
Device: cuda
Number of features: 1200
Label hierarchy: cell_type
Annotation levels weights using strategy 'linear_offset':
cell_type: 15 cell types, 1.0 relative weight
Dataset split:
Train dataset contains: 13738 cells, it is 80.0 % of input dataset
Validation dataset contains: 3435 cells, it is 20.0 % of input dataset
Unsupervised pretraining: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [01:03<00:00, 1.28s/it]
Training scAdam model: 9%|█████████▊ | 18/200 [00:19<03:19, 1.10s/it]
Early stopping triggered! Best score: 0.9539
Training completed!
Fitting unknown cells detector
UnknownCellDetector fitted successfully!
Model saved to model_scadam
[11]:
# Predict cell types using trained model
adata_test = scparadise.scadam.predict(
adata_test,
path_model = 'model_scadam'
)
scAdam model with unknown detector loaded from model_scadam
Gene alignment:
Model features: 1200
Matched features: 1200 (100.0%)
Predicting: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 72/72 [00:00<00:00, 142.93it/s]
Added cell type column: pred_celltype_l1
Added probabilities column: pred_celltype_l1_probability
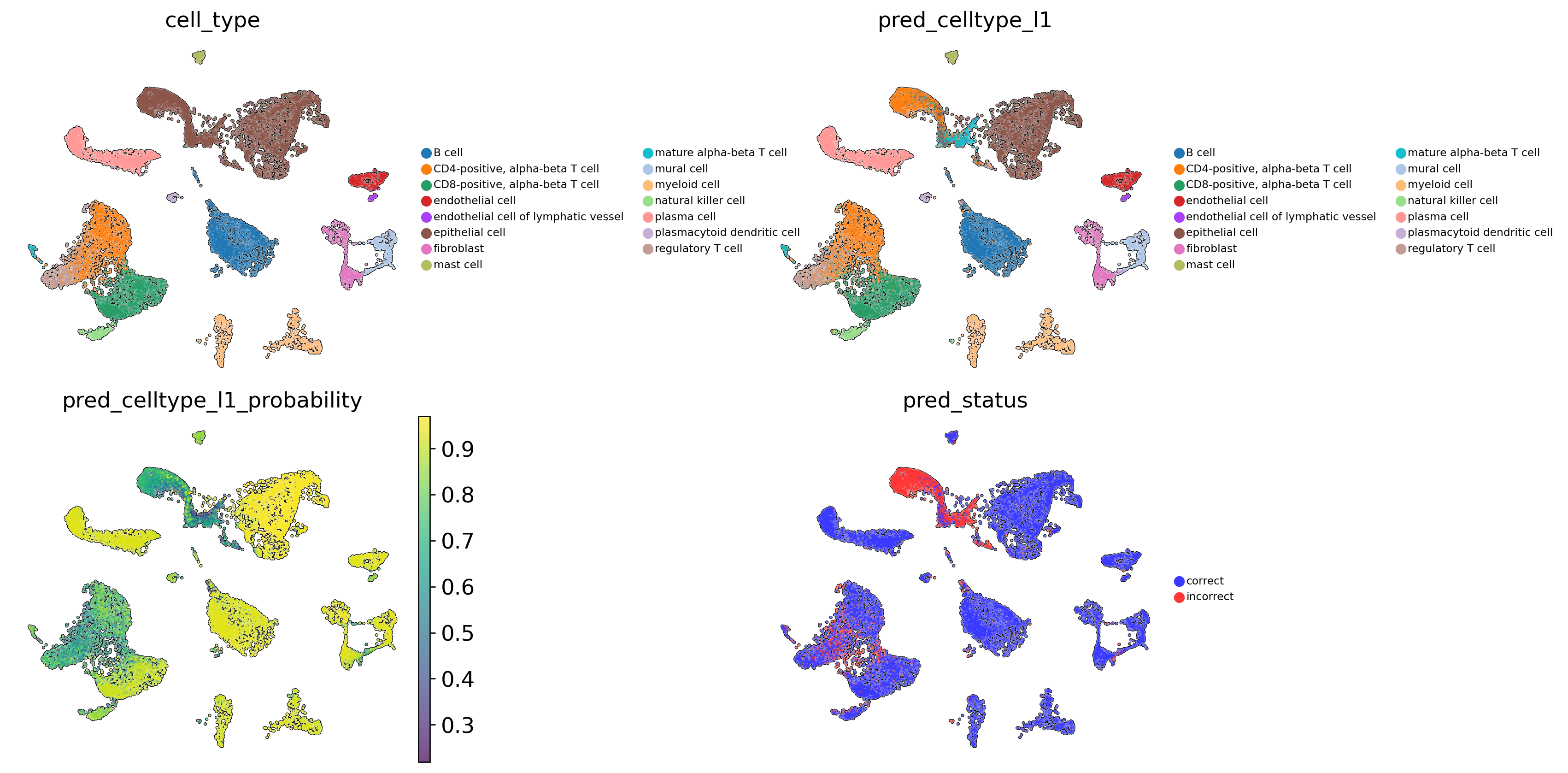
Evaluation of prediction quality#
The model cannot predict mature alpha-beta T cell (precision = 0.0777).
Also model cannot predict 50% of epithelial cell (recall/sensitivity = 0.5707).
There is also low sensitivity for regulatory T cell and low precision for CD8-positive and CD4-positive alpha-beta T cells, regulatory T cell, and endothelial cell.
[12]:
## Check model quality
df = scparadise.scnoah.report_classif_full(
adata_test,
celltype='cell_type',
pred_celltype='pred_celltype_l1'
)
df
[12]:
| precision | recall/sensitivity | specificity | f1-score | geometric mean | index balanced accuracy | number of cells | |
|---|---|---|---|---|---|---|---|
| B cell | 0.9467 | 0.98 | 0.993 | 0.9631 | 0.9865 | 0.9719 | 2050 |
| CD4-positive, alpha-beta T cell | 0.3068 | 0.8295 | 0.826 | 0.4479 | 0.8278 | 0.6854 | 1554 |
| CD8-positive, alpha-beta T cell | 0.8736 | 0.9248 | 0.9859 | 0.8985 | 0.9549 | 0.9062 | 1742 |
| endothelial cell | 0.9870 | 0.9956 | 0.9997 | 0.9913 | 0.9976 | 0.9949 | 457 |
| endothelial cell of lymphatic vessel | 1.0000 | 0.8462 | 1.0 | 0.9167 | 0.9199 | 0.8331 | 52 |
| epithelial cell | 0.9953 | 0.4803 | 0.9984 | 0.648 | 0.6925 | 0.4547 | 7505 |
| fibroblast | 0.9736 | 0.9837 | 0.999 | 0.9787 | 0.9913 | 0.9812 | 676 |
| mast cell | 0.9861 | 0.9595 | 0.9999 | 0.9726 | 0.9795 | 0.9555 | 148 |
| mature alpha-beta T cell | 0.1017 | 0.8667 | 0.9685 | 0.1821 | 0.9162 | 0.8308 | 75 |
| mural cell | 0.9724 | 0.9657 | 0.9993 | 0.969 | 0.9824 | 0.9618 | 437 |
| myeloid cell | 0.9902 | 0.9766 | 0.9996 | 0.9834 | 0.988 | 0.9739 | 726 |
| natural killer cell | 0.8811 | 0.8969 | 0.9985 | 0.8889 | 0.9463 | 0.8864 | 223 |
| plasma cell | 0.9825 | 0.9974 | 0.9979 | 0.9899 | 0.9977 | 0.9953 | 1919 |
| plasmacytoid dendritic cell | 0.9231 | 0.96 | 0.9998 | 0.9412 | 0.9797 | 0.956 | 50 |
| regulatory T cell | 0.4664 | 0.7901 | 0.9648 | 0.5866 | 0.8731 | 0.749 | 686 |
| macro avg | 0.8258 | 0.8969 | 0.982 | 0.8238 | 0.9356 | 0.8757 | |
| weighted avg | 0.8916 | 0.7497 | 0.9807 | 0.7707 | 0.8457 | 0.7219 | |
| Accuracy | 0.7497 | ||||||
| Balanced accuracy | 0.8969 |
[13]:
# Order cell type colors
celltype = np.unique(adata_test.obs['cell_type']).tolist()
adata_test.obs['cell_type'] = pd.Categorical(
values=adata_test.obs['cell_type'], categories=celltype, ordered=True
)
adata_test.obs['pred_celltype_l1'] = pd.Categorical(
values=adata_test.obs['pred_celltype_l1'], categories=celltype, ordered=True
)
scparadise.scnoah.pred_status(adata_test, celltype='cell_type', pred_celltype='pred_celltype_l1')
[14]:
# Visualise predicted cell types levels, prediction probabilities and prediction status
sc.pl.umap(
adata_test,
color=[
'cell_type',
'pred_celltype_l1',
'pred_celltype_l1_probability',
'pred_status'
],
frameon = False,
add_outline = True,
legend_loc = 'right margin',
legend_fontsize = 7,
legend_fontoutline = 1,
ncols=2,
wspace = 0.7,
hspace = 0.1
)
Warm start model training#
Warning! For warm start scAdam model training, a dataset is required that contains all the same cell types that were present in the original training. The cell types must be named exactly as they were during the initial training of the model.
There should be no new additional cell types or levels of annotation.
Additionally, none of the cell types used for the initial training of the model should be missing.
[15]:
# Warm start requires second training dataset and path to pretrained model
scparadise.scadam.warm_start(
adata_train_2,
path='', # path to save model
path_model='model_scadam', # folder name with pretrained model
model_name='model_scadam_warm_start', # folder name with fine-tuned model
celltype_keys=['cell_type'],
eval_metric=['accuracy', 'balanced_accuracy']
)
scAdam model with unknown detector loaded from model_scadam
Device: cuda
Gene alignment:
Number of features: 1200
Matched features: 1200 (100.0%)
Label hierarchy: cell_type
Annotation levels weights using strategy 'linear_offset':
cell_type: 15 cell types, 1.0 relative weight
Dataset split:
Train dataset contains: 25740 cells, it is 80.0 % of input dataset
Validation dataset contains: 6436 cells, it is 20.0 % of input dataset
Warm-start model fine-tuning: 34%|██████████████████████████████████▋ | 34/100 [01:10<02:17, 2.09s/it]
Early stopping triggered! Best score: 0.9508
Fitting unknown cells detector
UnknownCellDetector fitted successfully!
Model saved to model_scadam_warm_start
[16]:
# Predict cell types using trained model
adata_test = scparadise.scadam.predict(
adata_test,
path_model = 'model_scadam_warm_start'
)
scAdam model with unknown detector loaded from model_scadam_warm_start
Gene alignment:
Model features: 1200
Matched features: 1200 (100.0%)
Predicting: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 72/72 [00:00<00:00, 155.05it/s]
Added cell type column: pred_celltype_l1
Added probabilities column: pred_celltype_l1_probability
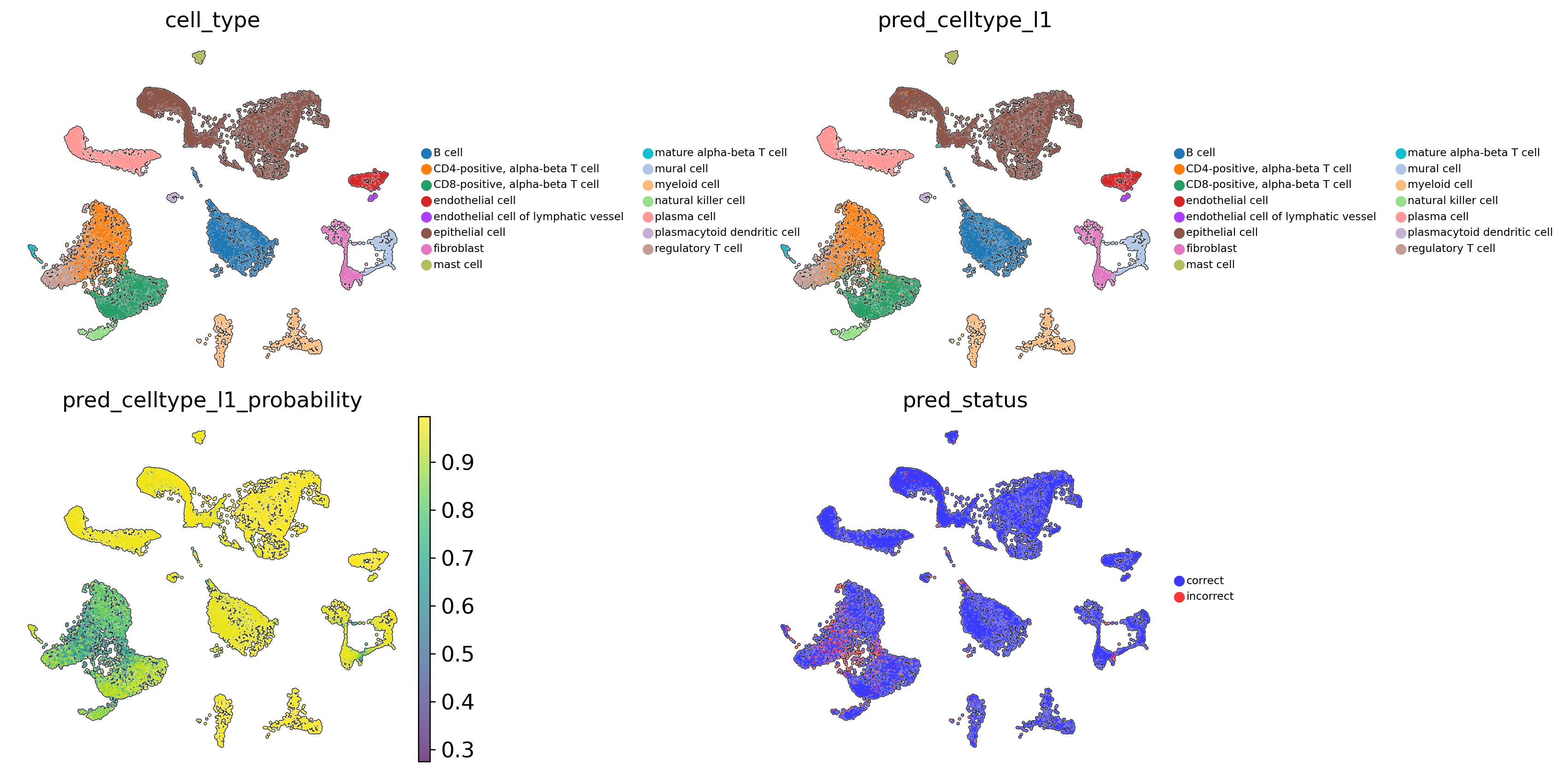
Evaluation of prediction results#
Warm start leads to an increase in the model’s accuracy (+17.1%), balanced accuracy (+4.3%), precision (+9.5%), f1-score (+10.2%), geometric mean (+3%), and index balanced accuracy (+5.5%).
Below are examples of improved model performance for certain cell types.
mature alpha-beta T cell(precision - 0.6542 vs 0.0777)regulatory T cell(precision - 0.7391 vs 0.5817)epithelial cell(sensitivity - 0.9819 vs 0.5707)CD4-positive, alpha-beta T cell(precision - 0.8379 vs 0.4094)CD8-positive, alpha-beta T cell(precision - 0.9052 vs 0.7899)endothelial cell of lymphatic vessel(sensitivity - 0.9615 vs 0.8269)
Full comparison is available below.
[17]:
## Check model quality
df_warm_start = scparadise.scnoah.report_classif_full(
adata_test,
celltype='cell_type',
pred_celltype='pred_celltype_l1'
)
df_warm_start
[17]:
| precision | recall/sensitivity | specificity | f1-score | geometric mean | index balanced accuracy | number of cells | |
|---|---|---|---|---|---|---|---|
| B cell | 0.9901 | 0.9776 | 0.9988 | 0.9838 | 0.9881 | 0.9743 | 2050 |
| CD4-positive, alpha-beta T cell | 0.8621 | 0.861 | 0.9872 | 0.8616 | 0.922 | 0.8393 | 1554 |
| CD8-positive, alpha-beta T cell | 0.9274 | 0.9099 | 0.9925 | 0.9186 | 0.9503 | 0.8956 | 1742 |
| endothelial cell | 0.9978 | 0.9978 | 0.9999 | 0.9978 | 0.9989 | 0.9975 | 457 |
| endothelial cell of lymphatic vessel | 1.0000 | 0.9808 | 1.0 | 0.9903 | 0.9903 | 0.9789 | 52 |
| epithelial cell | 0.9928 | 0.9861 | 0.995 | 0.9894 | 0.9906 | 0.9803 | 7505 |
| fibroblast | 0.9881 | 0.9793 | 0.9995 | 0.9837 | 0.9894 | 0.9769 | 676 |
| mast cell | 0.9797 | 0.9797 | 0.9998 | 0.9797 | 0.9897 | 0.9776 | 148 |
| mature alpha-beta T cell | 0.8375 | 0.8933 | 0.9993 | 0.8645 | 0.9448 | 0.8832 | 75 |
| mural cell | 0.9515 | 0.9886 | 0.9988 | 0.9697 | 0.9937 | 0.9863 | 437 |
| myeloid cell | 0.9875 | 0.9793 | 0.9995 | 0.9834 | 0.9894 | 0.9769 | 726 |
| natural killer cell | 0.7553 | 0.9552 | 0.9962 | 0.8436 | 0.9755 | 0.9476 | 223 |
| plasma cell | 0.9876 | 0.9953 | 0.9985 | 0.9914 | 0.9969 | 0.9935 | 1919 |
| plasmacytoid dendritic cell | 0.9608 | 0.98 | 0.9999 | 0.9703 | 0.9899 | 0.9779 | 50 |
| regulatory T cell | 0.7447 | 0.7741 | 0.9897 | 0.7591 | 0.8752 | 0.7495 | 686 |
| macro avg | 0.9309 | 0.9492 | 0.997 | 0.9391 | 0.9723 | 0.9424 | |
| weighted avg | 0.9604 | 0.9593 | 0.9954 | 0.9596 | 0.9768 | 0.9518 | |
| Accuracy | 0.9593 | ||||||
| Balanced accuracy | 0.9492 |
[18]:
# Order cell type colors
celltype = np.unique(adata_test.obs['cell_type']).tolist()
adata_test.obs['cell_type'] = pd.Categorical(
values=adata_test.obs['cell_type'], categories=celltype, ordered=True
)
adata_test.obs['pred_celltype_l1'] = pd.Categorical(
values=adata_test.obs['pred_celltype_l1'], categories=celltype, ordered=True
)
# Add prediction status. Label cells as correct or incorrect based on the comparison between ground truth cell types and predictions.
scparadise.scnoah.pred_status(adata_test, celltype='cell_type', pred_celltype='pred_celltype_l1')
[19]:
# Visualise predicted cell types levels, prediction probabilities and prediction status
sc.pl.umap(
adata_test,
color=[
'cell_type',
'pred_celltype_l1',
'pred_celltype_l1_probability',
'pred_status'
],
frameon = False,
add_outline = True,
legend_loc = 'right margin',
legend_fontsize = 7,
legend_fontoutline = 1,
ncols=2,
wspace = 0.7,
hspace = 0.1
)
[20]:
# Compare prediction results
# 'untuned' row represents untuned model
# 'warm start' row represents warm start trained model
df.compare(df_warm_start, keep_equal=True, align_axis = 0, result_names=('untuned', 'warm start'))
[20]:
| precision | recall/sensitivity | specificity | f1-score | geometric mean | index balanced accuracy | ||
|---|---|---|---|---|---|---|---|
| B cell | untuned | 0.9467 | 0.98 | 0.993 | 0.9631 | 0.9865 | 0.9719 |
| warm start | 0.9901 | 0.9776 | 0.9988 | 0.9838 | 0.9881 | 0.9743 | |
| CD4-positive, alpha-beta T cell | untuned | 0.3068 | 0.8295 | 0.826 | 0.4479 | 0.8278 | 0.6854 |
| warm start | 0.8621 | 0.861 | 0.9872 | 0.8616 | 0.922 | 0.8393 | |
| CD8-positive, alpha-beta T cell | untuned | 0.8736 | 0.9248 | 0.9859 | 0.8985 | 0.9549 | 0.9062 |
| warm start | 0.9274 | 0.9099 | 0.9925 | 0.9186 | 0.9503 | 0.8956 | |
| endothelial cell | untuned | 0.9870 | 0.9956 | 0.9997 | 0.9913 | 0.9976 | 0.9949 |
| warm start | 0.9978 | 0.9978 | 0.9999 | 0.9978 | 0.9989 | 0.9975 | |
| endothelial cell of lymphatic vessel | untuned | 1.0000 | 0.8462 | 1.0 | 0.9167 | 0.9199 | 0.8331 |
| warm start | 1.0000 | 0.9808 | 1.0 | 0.9903 | 0.9903 | 0.9789 | |
| epithelial cell | untuned | 0.9953 | 0.4803 | 0.9984 | 0.648 | 0.6925 | 0.4547 |
| warm start | 0.9928 | 0.9861 | 0.995 | 0.9894 | 0.9906 | 0.9803 | |
| fibroblast | untuned | 0.9736 | 0.9837 | 0.999 | 0.9787 | 0.9913 | 0.9812 |
| warm start | 0.9881 | 0.9793 | 0.9995 | 0.9837 | 0.9894 | 0.9769 | |
| mast cell | untuned | 0.9861 | 0.9595 | 0.9999 | 0.9726 | 0.9795 | 0.9555 |
| warm start | 0.9797 | 0.9797 | 0.9998 | 0.9797 | 0.9897 | 0.9776 | |
| mature alpha-beta T cell | untuned | 0.1017 | 0.8667 | 0.9685 | 0.1821 | 0.9162 | 0.8308 |
| warm start | 0.8375 | 0.8933 | 0.9993 | 0.8645 | 0.9448 | 0.8832 | |
| mural cell | untuned | 0.9724 | 0.9657 | 0.9993 | 0.969 | 0.9824 | 0.9618 |
| warm start | 0.9515 | 0.9886 | 0.9988 | 0.9697 | 0.9937 | 0.9863 | |
| myeloid cell | untuned | 0.9902 | 0.9766 | 0.9996 | 0.9834 | 0.988 | 0.9739 |
| warm start | 0.9875 | 0.9793 | 0.9995 | 0.9834 | 0.9894 | 0.9769 | |
| natural killer cell | untuned | 0.8811 | 0.8969 | 0.9985 | 0.8889 | 0.9463 | 0.8864 |
| warm start | 0.7553 | 0.9552 | 0.9962 | 0.8436 | 0.9755 | 0.9476 | |
| plasma cell | untuned | 0.9825 | 0.9974 | 0.9979 | 0.9899 | 0.9977 | 0.9953 |
| warm start | 0.9876 | 0.9953 | 0.9985 | 0.9914 | 0.9969 | 0.9935 | |
| plasmacytoid dendritic cell | untuned | 0.9231 | 0.96 | 0.9998 | 0.9412 | 0.9797 | 0.956 |
| warm start | 0.9608 | 0.98 | 0.9999 | 0.9703 | 0.9899 | 0.9779 | |
| regulatory T cell | untuned | 0.4664 | 0.7901 | 0.9648 | 0.5866 | 0.8731 | 0.749 |
| warm start | 0.7447 | 0.7741 | 0.9897 | 0.7591 | 0.8752 | 0.7495 | |
| macro avg | untuned | 0.8258 | 0.8969 | 0.982 | 0.8238 | 0.9356 | 0.8757 |
| warm start | 0.9309 | 0.9492 | 0.997 | 0.9391 | 0.9723 | 0.9424 | |
| weighted avg | untuned | 0.8916 | 0.7497 | 0.9807 | 0.7707 | 0.8457 | 0.7219 |
| warm start | 0.9604 | 0.9593 | 0.9954 | 0.9596 | 0.9768 | 0.9518 | |
| Accuracy | untuned | 0.7497 | |||||
| warm start | 0.9593 | ||||||
| Balanced accuracy | untuned | 0.8969 | |||||
| warm start | 0.9492 |
Hyperparameters tuning#
Warning! Hyperparameter tuning is a very time-consuming process and may be interrupted for various reasons (such as system shutdowns or errors in CUDA). However, this is not a problem, as restarting the hyperparameter tuning will allow it to continue from the last unfinished trial. An example of hyperparameter tuning represents such a case. The fourth line states: “Using an existing study with name ‘model_scadam_hp_tune’ instead of creating a new one.” This indicates a restart of hyperparameter tuning (in this case, from the 8th trial).
[21]:
scparadise.scadam.hyperparameter_tuning(
adata_train_1,
path='',
model_name='model_scadam_hp_tune', # Folder to save hyperparameter tuning results
celltype_keys=['cell_type'],
num_trials=100, # The number of attempts to find the optimal hyperparameters for the model (recommended - minimum 100)
eval_metric=['accuracy', 'balanced_accuracy']
)
Device: cuda
Number of features: 1200
Number of cells: 17173
Label hierarchy: cell_type
Annotation levels weights using strategy 'linear_offset':
cell_type: 15 cell types, 1.0 relative weight
Start model optimization using optuna...
[I 2026-01-28 13:17:47,694] A new study created in RDB with name: study
Fold 1 finished with balanced_accuracy value = 0.948972
Fold 2 finished with balanced_accuracy value = 0.965498
Fold 3 finished with balanced_accuracy value = 0.957539
Fold 4 finished with balanced_accuracy value = 0.955547
Fold 5 finished with balanced_accuracy value = 0.964587
[I 2026-01-28 13:25:47,549] Trial 0 finished with value: 0.9584284606002733 and parameters: {'nc': 16, 'nb': 5, 'nh': 8, 'ed_nh_ratio': 32, 'ff_hd': 512, 'classifier_hd': 256, 'dropout': 0.3, 'lr': 0.0001, 'weight_decay': 0.0001, 'batch_size': 128, 'patience': 10, 'epochs': 200, 'use_augmentation': True, 'aug_probability': 0.5, 'prob': 0.15, 'noise_std': 0.1, 'dropout_aug': 0.1, 'alpha': 0.2, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.946358
Fold 2 finished with balanced_accuracy value = 0.947439
Fold 3 finished with balanced_accuracy value = 0.947981
Fold 4 finished with balanced_accuracy value = 0.943022
Fold 5 finished with balanced_accuracy value = 0.953465
[I 2026-01-28 13:28:38,810] Trial 1 finished with value: 0.9476529258450966 and parameters: {'nc': 6, 'nb': 3, 'nh': 14, 'ed_nh_ratio': 12, 'ff_hd': 384, 'classifier_hd': 640, 'dropout': 0.4824608705248689, 'lr': 7.58857436196009e-05, 'weight_decay': 8.21463012102524e-05, 'batch_size': 1152, 'patience': 30, 'epochs': 130, 'use_augmentation': True, 'aug_probability': 0.7081793053774956, 'prob': 0.2371900757081571, 'noise_std': 0.37682167858855964, 'dropout_aug': 0.39112455639519045, 'alpha': 0.38542292662934396, 'from_unsupervised': False, 'pretrain_epochs': 20}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.943171
Fold 2 finished with balanced_accuracy value = 0.936478
Fold 3 finished with balanced_accuracy value = 0.947089
Fold 4 finished with balanced_accuracy value = 0.922384
Fold 5 finished with balanced_accuracy value = 0.945823
[I 2026-01-28 13:29:32,157] Trial 2 finished with value: 0.9389890149635098 and parameters: {'nc': 2, 'nb': 6, 'nh': 8, 'ed_nh_ratio': 32, 'ff_hd': 896, 'classifier_hd': 1024, 'dropout': 0.29841921554172546, 'lr': 0.0022627084817633406, 'weight_decay': 3.831164143964319e-05, 'batch_size': 192, 'patience': 5, 'epochs': 125, 'use_augmentation': True, 'aug_probability': 0.3854528149106472, 'prob': 0.1924530883132387, 'noise_std': 0.13526561159559405, 'dropout_aug': 0.30153827341585404, 'alpha': 0.20385996156524322, 'from_unsupervised': False, 'pretrain_epochs': 10}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.950436
Fold 2 finished with balanced_accuracy value = 0.941307
Fold 3 finished with balanced_accuracy value = 0.937843
[I 2026-01-28 13:30:05,862] Trial 3 pruned.
Fold 1 finished with balanced_accuracy value = 0.944340
[I 2026-01-28 13:30:27,575] Trial 4 pruned.
Fold 1 finished with balanced_accuracy value = 0.948075
Fold 2 finished with balanced_accuracy value = 0.953882
Fold 3 finished with balanced_accuracy value = 0.950558
Fold 4 finished with balanced_accuracy value = 0.944801
Fold 5 finished with balanced_accuracy value = 0.958147
[I 2026-01-28 13:33:24,974] Trial 5 finished with value: 0.9510925913324222 and parameters: {'nc': 14, 'nb': 3, 'nh': 12, 'ed_nh_ratio': 8, 'ff_hd': 256, 'classifier_hd': 128, 'dropout': 0.20211073545391373, 'lr': 0.00016212156642828472, 'weight_decay': 2.9960317755483094e-06, 'batch_size': 1344, 'patience': 20, 'epochs': 140, 'use_augmentation': True, 'aug_probability': 0.37811126985748766, 'prob': 0.09566177563874514, 'noise_std': 0.31550509041610686, 'dropout_aug': 0.06240293069001002, 'alpha': 0.39644143868112536, 'from_unsupervised': False, 'pretrain_epochs': 35}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.951800
Fold 2 finished with balanced_accuracy value = 0.940676
Fold 3 finished with balanced_accuracy value = 0.951326
Fold 4 finished with balanced_accuracy value = 0.943189
Fold 5 finished with balanced_accuracy value = 0.955374
[I 2026-01-28 13:35:34,249] Trial 6 finished with value: 0.9484729812057398 and parameters: {'nc': 8, 'nb': 3, 'nh': 10, 'ed_nh_ratio': 8, 'ff_hd': 640, 'classifier_hd': 256, 'dropout': 0.3574518077160684, 'lr': 0.00012880530574286306, 'weight_decay': 7.068385112054628e-06, 'batch_size': 1216, 'patience': 15, 'epochs': 145, 'use_augmentation': True, 'aug_probability': 0.21837134362940533, 'prob': 0.22906644777099444, 'noise_std': 0.20536479059726775, 'dropout_aug': 0.1560911726095887, 'alpha': 0.30116765456626404, 'from_unsupervised': False, 'pretrain_epochs': 65}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.801784
[I 2026-01-28 13:36:03,853] Trial 7 pruned.
Fold 1 finished with balanced_accuracy value = 0.789370
Fold 2 finished with balanced_accuracy value = 0.814440
Fold 3 finished with balanced_accuracy value = 0.790613
[I 2026-01-28 13:37:01,414] Trial 8 pruned.
Fold 1 finished with balanced_accuracy value = 0.956409
Fold 2 finished with balanced_accuracy value = 0.952157
Fold 3 finished with balanced_accuracy value = 0.959800
Fold 4 finished with balanced_accuracy value = 0.955670
Fold 5 finished with balanced_accuracy value = 0.960212
[I 2026-01-28 13:41:13,917] Trial 9 finished with value: 0.9568498046334758 and parameters: {'nc': 6, 'nb': 3, 'nh': 16, 'ed_nh_ratio': 28, 'ff_hd': 640, 'classifier_hd': 128, 'dropout': 0.03597703023840432, 'lr': 8.360336304856504e-05, 'weight_decay': 1.7886060638254554e-05, 'batch_size': 320, 'patience': 5, 'epochs': 90, 'use_augmentation': True, 'aug_probability': 0.9703235281539149, 'prob': 0.133970610667682, 'noise_std': 0.13717300684779704, 'dropout_aug': 0.23182194553408794, 'alpha': 0.1704563968594891, 'from_unsupervised': True, 'pretrain_epochs': 75}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.566887
Fold 2 finished with balanced_accuracy value = 0.599458
Fold 3 finished with balanced_accuracy value = 0.593979
[I 2026-01-28 13:45:15,914] Trial 10 pruned.
Fold 1 finished with balanced_accuracy value = 0.953494
Fold 2 finished with balanced_accuracy value = 0.954753
Fold 3 finished with balanced_accuracy value = 0.953902
[I 2026-01-28 13:54:59,719] Trial 11 pruned.
Fold 1 finished with balanced_accuracy value = 0.915965
Fold 2 finished with balanced_accuracy value = 0.924208
Fold 3 finished with balanced_accuracy value = 0.933687
[I 2026-01-28 13:57:27,419] Trial 12 pruned.
Fold 1 finished with balanced_accuracy value = 0.950090
Fold 2 finished with balanced_accuracy value = 0.954502
Fold 3 finished with balanced_accuracy value = 0.954295
Fold 4 finished with balanced_accuracy value = 0.955398
Fold 5 finished with balanced_accuracy value = 0.958477
[I 2026-01-28 14:01:36,662] Trial 13 finished with value: 0.9545524070494938 and parameters: {'nc': 10, 'nb': 4, 'nh': 4, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.44962875774364186, 'lr': 0.0005155144493229978, 'weight_decay': 0.00028990427441156206, 'batch_size': 320, 'patience': 10, 'epochs': 175, 'use_augmentation': True, 'aug_probability': 0.8125847668887023, 'prob': 0.3790659527483653, 'noise_std': 0.21481744653817958, 'dropout_aug': 0.12429313178955564, 'alpha': 0.11646850244923157, 'from_unsupervised': True, 'pretrain_epochs': 75}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.943251
[I 2026-01-28 14:02:32,617] Trial 14 pruned.
Fold 1 finished with balanced_accuracy value = 0.945266
Fold 2 finished with balanced_accuracy value = 0.957213
Fold 3 finished with balanced_accuracy value = 0.955739
Fold 4 finished with balanced_accuracy value = 0.950337
Fold 5 finished with balanced_accuracy value = 0.962670
[I 2026-01-28 14:05:21,274] Trial 15 finished with value: 0.9542448997779751 and parameters: {'nc': 12, 'nb': 4, 'nh': 6, 'ed_nh_ratio': 24, 'ff_hd': 768, 'classifier_hd': 256, 'dropout': 0.10156346311647188, 'lr': 0.0004178130315878287, 'weight_decay': 0.0014324740062679143, 'batch_size': 512, 'patience': 10, 'epochs': 70, 'use_augmentation': True, 'aug_probability': 0.3472353198968007, 'prob': 0.1423206694485738, 'noise_std': 0.003969052256768815, 'dropout_aug': 0.009611915586473119, 'alpha': 0.056551228013035776, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 0 with value: 0.9584284606002733.
Fold 1 finished with balanced_accuracy value = 0.944502
[I 2026-01-28 14:06:08,480] Trial 16 pruned.
Fold 1 finished with balanced_accuracy value = 0.951437
[I 2026-01-28 14:06:48,985] Trial 17 pruned.
Fold 1 finished with balanced_accuracy value = 0.949402
Fold 2 finished with balanced_accuracy value = 0.960808
Fold 3 finished with balanced_accuracy value = 0.960671
Fold 4 finished with balanced_accuracy value = 0.958750
Fold 5 finished with balanced_accuracy value = 0.966299
[I 2026-01-28 14:20:35,110] Trial 18 finished with value: 0.9591860315412027 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 32, 'ff_hd': 512, 'classifier_hd': 256, 'dropout': 0.06520875597221133, 'lr': 0.0002657333241553037, 'weight_decay': 5.448378666204583e-06, 'batch_size': 64, 'patience': 25, 'epochs': 110, 'use_augmentation': False, 'aug_probability': 0.6227161743276617, 'prob': 0.19031173693354134, 'noise_std': 0.09315144358875024, 'dropout_aug': 0.0997446868936453, 'alpha': 0.22338732803110015, 'from_unsupervised': True, 'pretrain_epochs': 45}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.949682
[I 2026-01-28 14:23:33,805] Trial 19 pruned.
Fold 1 finished with balanced_accuracy value = 0.932952
[I 2026-01-28 14:24:10,136] Trial 20 pruned.
Fold 1 finished with balanced_accuracy value = 0.947748
[I 2026-01-28 14:25:39,048] Trial 21 pruned.
Fold 1 finished with balanced_accuracy value = 0.954207
Fold 2 finished with balanced_accuracy value = 0.959629
Fold 3 finished with balanced_accuracy value = 0.960431
Fold 4 finished with balanced_accuracy value = 0.952881
Fold 5 finished with balanced_accuracy value = 0.963379
[I 2026-01-28 14:33:38,551] Trial 22 finished with value: 0.9581054828863017 and parameters: {'nc': 12, 'nb': 3, 'nh': 16, 'ed_nh_ratio': 28, 'ff_hd': 512, 'classifier_hd': 384, 'dropout': 0.14687754379653867, 'lr': 4.9682521225938315e-05, 'weight_decay': 3.3089384411294395e-06, 'batch_size': 256, 'patience': 20, 'epochs': 110, 'use_augmentation': False, 'aug_probability': 0.806540945221351, 'prob': 0.19714852694651358, 'noise_std': 0.1668182673072617, 'dropout_aug': 0.10313309399219658, 'alpha': 0.1765700690260748, 'from_unsupervised': True, 'pretrain_epochs': 75}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.952075
Fold 2 finished with balanced_accuracy value = 0.958349
Fold 3 finished with balanced_accuracy value = 0.960877
Fold 4 finished with balanced_accuracy value = 0.956461
Fold 5 finished with balanced_accuracy value = 0.963417
[I 2026-01-28 14:39:28,183] Trial 23 finished with value: 0.9582358517082726 and parameters: {'nc': 12, 'nb': 2, 'nh': 14, 'ed_nh_ratio': 32, 'ff_hd': 384, 'classifier_hd': 384, 'dropout': 0.14986857484368907, 'lr': 4.150532367965395e-05, 'weight_decay': 2.136181901591549e-06, 'batch_size': 192, 'patience': 20, 'epochs': 115, 'use_augmentation': False, 'aug_probability': 0.7883252421118184, 'prob': 0.20093847629766867, 'noise_std': 0.2594312987620362, 'dropout_aug': 0.11653017251487661, 'alpha': 0.22196877221326444, 'from_unsupervised': True, 'pretrain_epochs': 60}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.947501
[I 2026-01-28 14:41:51,260] Trial 24 pruned.
Fold 1 finished with balanced_accuracy value = 0.952878
Fold 2 finished with balanced_accuracy value = 0.955457
Fold 3 finished with balanced_accuracy value = 0.960071
Fold 4 finished with balanced_accuracy value = 0.959471
Fold 5 finished with balanced_accuracy value = 0.961509
[I 2026-01-28 14:46:38,958] Trial 25 finished with value: 0.9578772713216159 and parameters: {'nc': 12, 'nb': 4, 'nh': 12, 'ed_nh_ratio': 24, 'ff_hd': 384, 'classifier_hd': 256, 'dropout': 0.3135795539682013, 'lr': 0.00022724718894226155, 'weight_decay': 0.0028140337787345934, 'batch_size': 448, 'patience': 20, 'epochs': 120, 'use_augmentation': False, 'aug_probability': 0.45696334552812723, 'prob': 0.32084371197234857, 'noise_std': 0.24940593679894313, 'dropout_aug': 0.1445865940012706, 'alpha': 0.32523233122801287, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.947410
[I 2026-01-28 14:48:40,432] Trial 26 pruned.
Fold 1 finished with balanced_accuracy value = 0.652710
Fold 2 finished with balanced_accuracy value = 0.654244
Fold 3 finished with balanced_accuracy value = 0.653868
[I 2026-01-28 14:51:31,922] Trial 27 pruned.
Fold 1 finished with balanced_accuracy value = 0.952662
Fold 2 finished with balanced_accuracy value = 0.958975
Fold 3 finished with balanced_accuracy value = 0.956966
[I 2026-01-28 14:52:44,896] Trial 28 pruned.
Fold 1 finished with balanced_accuracy value = 0.950198
[I 2026-01-28 14:53:42,910] Trial 29 pruned.
Fold 1 finished with balanced_accuracy value = 0.948191
[I 2026-01-28 14:54:29,608] Trial 30 pruned.
Fold 1 finished with balanced_accuracy value = 0.950301
[I 2026-01-28 14:56:02,803] Trial 31 pruned.
Fold 1 finished with balanced_accuracy value = 0.947621
[I 2026-01-28 14:58:04,044] Trial 32 pruned.
Fold 1 finished with balanced_accuracy value = 0.950098
[I 2026-01-28 14:59:07,797] Trial 33 pruned.
Fold 1 finished with balanced_accuracy value = 0.950890
Fold 2 finished with balanced_accuracy value = 0.959007
Fold 3 finished with balanced_accuracy value = 0.954376
[I 2026-01-28 15:02:06,047] Trial 34 pruned.
Fold 1 finished with balanced_accuracy value = 0.952891
Fold 2 finished with balanced_accuracy value = 0.956715
Fold 3 finished with balanced_accuracy value = 0.956272
Fold 4 finished with balanced_accuracy value = 0.954420
Fold 5 finished with balanced_accuracy value = 0.961489
[I 2026-01-28 15:06:04,550] Trial 35 finished with value: 0.9563573312876551 and parameters: {'nc': 14, 'nb': 5, 'nh': 16, 'ed_nh_ratio': 12, 'ff_hd': 256, 'classifier_hd': 512, 'dropout': 0.3163340297856858, 'lr': 0.00011132661394294421, 'weight_decay': 5.413872239110359e-05, 'batch_size': 192, 'patience': 25, 'epochs': 105, 'use_augmentation': False, 'aug_probability': 0.9072391301040963, 'prob': 0.22558813271950473, 'noise_std': 0.02995608310382375, 'dropout_aug': 0.07347065543730186, 'alpha': 0.1629768454447468, 'from_unsupervised': False, 'pretrain_epochs': 40}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.953722
Fold 2 finished with balanced_accuracy value = 0.957802
Fold 3 finished with balanced_accuracy value = 0.962542
Fold 4 finished with balanced_accuracy value = 0.953405
Fold 5 finished with balanced_accuracy value = 0.960221
[I 2026-01-28 15:12:24,033] Trial 36 finished with value: 0.9575381871126878 and parameters: {'nc': 8, 'nb': 6, 'nh': 8, 'ed_nh_ratio': 24, 'ff_hd': 512, 'classifier_hd': 256, 'dropout': 0.49559890042821786, 'lr': 0.00015506610259543574, 'weight_decay': 1.5413636715320286e-06, 'batch_size': 256, 'patience': 15, 'epochs': 140, 'use_augmentation': False, 'aug_probability': 0.6216427928249159, 'prob': 0.20828372410260826, 'noise_std': 0.12071940040508547, 'dropout_aug': 0.11165831484378672, 'alpha': 0.2702700447897006, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.951282
[I 2026-01-28 15:12:53,350] Trial 37 pruned.
Fold 1 finished with balanced_accuracy value = 0.936215
[I 2026-01-28 15:13:35,691] Trial 38 pruned.
Fold 1 finished with balanced_accuracy value = 0.954139
Fold 2 finished with balanced_accuracy value = 0.959835
Fold 3 finished with balanced_accuracy value = 0.959170
[I 2026-01-28 15:18:46,168] Trial 39 pruned.
Fold 1 finished with balanced_accuracy value = 0.945922
[I 2026-01-28 15:19:22,438] Trial 40 pruned.
Fold 1 finished with balanced_accuracy value = 0.950879
Fold 2 finished with balanced_accuracy value = 0.957598
Fold 3 finished with balanced_accuracy value = 0.958398
Fold 4 finished with balanced_accuracy value = 0.959575
Fold 5 finished with balanced_accuracy value = 0.965488
[I 2026-01-28 15:24:25,975] Trial 41 finished with value: 0.9583875518980547 and parameters: {'nc': 12, 'nb': 4, 'nh': 12, 'ed_nh_ratio': 24, 'ff_hd': 384, 'classifier_hd': 256, 'dropout': 0.3338953232797208, 'lr': 0.00023533895680379752, 'weight_decay': 0.002523721127301264, 'batch_size': 512, 'patience': 20, 'epochs': 125, 'use_augmentation': False, 'aug_probability': 0.4342041754337403, 'prob': 0.3729909340265848, 'noise_std': 0.2540816589595314, 'dropout_aug': 0.14717044857343065, 'alpha': 0.35297789144238345, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.948397
[I 2026-01-28 15:25:26,429] Trial 42 pruned.
Fold 1 finished with balanced_accuracy value = 0.950414
Fold 2 finished with balanced_accuracy value = 0.955461
Fold 3 finished with balanced_accuracy value = 0.959314
Fold 4 finished with balanced_accuracy value = 0.957676
Fold 5 finished with balanced_accuracy value = 0.960061
[I 2026-01-28 15:32:08,401] Trial 43 finished with value: 0.9565852966843862 and parameters: {'nc': 12, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 512, 'classifier_hd': 256, 'dropout': 0.33571043641723114, 'lr': 9.638071608501017e-05, 'weight_decay': 0.0002659741819556269, 'batch_size': 512, 'patience': 20, 'epochs': 125, 'use_augmentation': False, 'aug_probability': 0.32117671682153515, 'prob': 0.3884925756700578, 'noise_std': 0.23737908008038727, 'dropout_aug': 0.07316111957153759, 'alpha': 0.37598219100890895, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.951222
Fold 2 finished with balanced_accuracy value = 0.952656
Fold 3 finished with balanced_accuracy value = 0.958062
Fold 4 finished with balanced_accuracy value = 0.950690
Fold 5 finished with balanced_accuracy value = 0.957829
[I 2026-01-28 15:37:26,854] Trial 44 finished with value: 0.9540918930444823 and parameters: {'nc': 10, 'nb': 5, 'nh': 8, 'ed_nh_ratio': 28, 'ff_hd': 384, 'classifier_hd': 384, 'dropout': 0.3793252083177661, 'lr': 6.866685801527936e-05, 'weight_decay': 0.003494510386835045, 'batch_size': 384, 'patience': 20, 'epochs': 95, 'use_augmentation': False, 'aug_probability': 0.40913457649809293, 'prob': 0.14711905899967162, 'noise_std': 0.26565126523049093, 'dropout_aug': 0.14119329005296344, 'alpha': 0.09884607267063017, 'from_unsupervised': True, 'pretrain_epochs': 40}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.953174
Fold 2 finished with balanced_accuracy value = 0.958597
Fold 3 finished with balanced_accuracy value = 0.954167
[I 2026-01-28 15:46:47,769] Trial 45 pruned.
Fold 1 finished with balanced_accuracy value = 0.953271
Fold 2 finished with balanced_accuracy value = 0.958624
Fold 3 finished with balanced_accuracy value = 0.958068
[I 2026-01-28 15:50:06,348] Trial 46 pruned.
Fold 1 finished with balanced_accuracy value = 0.948046
[I 2026-01-28 15:50:59,510] Trial 47 pruned.
Fold 1 finished with balanced_accuracy value = 0.956033
Fold 2 finished with balanced_accuracy value = 0.957387
Fold 3 finished with balanced_accuracy value = 0.961410
Fold 4 finished with balanced_accuracy value = 0.954751
Fold 5 finished with balanced_accuracy value = 0.964724
[I 2026-01-28 15:58:49,459] Trial 48 finished with value: 0.9588609966464938 and parameters: {'nc': 8, 'nb': 5, 'nh': 16, 'ed_nh_ratio': 32, 'ff_hd': 768, 'classifier_hd': 256, 'dropout': 0.29575125409618713, 'lr': 0.00046725240922284515, 'weight_decay': 0.0010706808884051377, 'batch_size': 384, 'patience': 20, 'epochs': 115, 'use_augmentation': True, 'aug_probability': 0.2699762032224959, 'prob': 0.36892668999026124, 'noise_std': 0.3457258441716189, 'dropout_aug': 0.1309427643634, 'alpha': 0.29092415340756683, 'from_unsupervised': True, 'pretrain_epochs': 55}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.952066
Fold 2 finished with balanced_accuracy value = 0.957494
Fold 3 finished with balanced_accuracy value = 0.956793
[I 2026-01-28 16:02:36,794] Trial 49 pruned.
Fold 1 finished with balanced_accuracy value = 0.950137
[I 2026-01-28 16:03:24,331] Trial 50 pruned.
Fold 1 finished with balanced_accuracy value = 0.954560
Fold 2 finished with balanced_accuracy value = 0.956436
Fold 3 finished with balanced_accuracy value = 0.955038
[I 2026-01-28 16:07:17,002] Trial 51 pruned.
Fold 1 finished with balanced_accuracy value = 0.953062
Fold 2 finished with balanced_accuracy value = 0.959772
Fold 3 finished with balanced_accuracy value = 0.958245
Fold 4 finished with balanced_accuracy value = 0.957845
Fold 5 finished with balanced_accuracy value = 0.961629
[I 2026-01-28 16:16:18,317] Trial 52 finished with value: 0.9581106106287699 and parameters: {'nc': 10, 'nb': 4, 'nh': 16, 'ed_nh_ratio': 32, 'ff_hd': 512, 'classifier_hd': 256, 'dropout': 0.21003127583120984, 'lr': 0.0011649711876860823, 'weight_decay': 0.0009080029373259317, 'batch_size': 128, 'patience': 20, 'epochs': 115, 'use_augmentation': True, 'aug_probability': 0.5046166780426251, 'prob': 0.3681064179115941, 'noise_std': 0.2987596409916651, 'dropout_aug': 0.07809389842042419, 'alpha': 0.23605004517835307, 'from_unsupervised': True, 'pretrain_epochs': 45}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.948526
Fold 2 finished with balanced_accuracy value = 0.958600
Fold 3 finished with balanced_accuracy value = 0.955417
[I 2026-01-28 16:24:06,264] Trial 53 pruned.
Fold 1 finished with balanced_accuracy value = 0.952044
Fold 2 finished with balanced_accuracy value = 0.952140
Fold 3 finished with balanced_accuracy value = 0.957286
[I 2026-01-28 16:28:29,656] Trial 54 pruned.
Fold 1 finished with balanced_accuracy value = 0.934961
[I 2026-01-28 16:31:47,758] Trial 55 pruned.
Fold 1 finished with balanced_accuracy value = 0.947181
Fold 2 finished with balanced_accuracy value = 0.951956
Fold 3 finished with balanced_accuracy value = 0.958400
Fold 4 finished with balanced_accuracy value = 0.945896
Fold 5 finished with balanced_accuracy value = 0.959466
[I 2026-01-28 16:38:00,374] Trial 56 finished with value: 0.9525799780223864 and parameters: {'nc': 10, 'nb': 8, 'nh': 16, 'ed_nh_ratio': 8, 'ff_hd': 640, 'classifier_hd': 256, 'dropout': 0.2627680555997178, 'lr': 0.0008533778429695596, 'weight_decay': 0.009213627763884909, 'batch_size': 384, 'patience': 25, 'epochs': 50, 'use_augmentation': True, 'aug_probability': 0.521041345005198, 'prob': 0.3801634123622139, 'noise_std': 0.2919927651878329, 'dropout_aug': 0.0477288877442322, 'alpha': 0.22676262118721158, 'from_unsupervised': True, 'pretrain_epochs': 45}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.946086
[I 2026-01-28 16:38:31,085] Trial 57 pruned.
Fold 1 finished with balanced_accuracy value = 0.945623
Fold 2 finished with balanced_accuracy value = 0.943263
Fold 3 finished with balanced_accuracy value = 0.954802
[I 2026-01-28 16:40:39,791] Trial 58 pruned.
Fold 1 finished with balanced_accuracy value = 0.946333
[I 2026-01-28 16:41:07,138] Trial 59 pruned.
Fold 1 finished with balanced_accuracy value = 0.954038
Fold 2 finished with balanced_accuracy value = 0.954289
Fold 3 finished with balanced_accuracy value = 0.960369
Fold 4 finished with balanced_accuracy value = 0.956145
Fold 5 finished with balanced_accuracy value = 0.964977
[I 2026-01-28 16:54:37,367] Trial 60 finished with value: 0.9579637404565358 and parameters: {'nc': 16, 'nb': 6, 'nh': 16, 'ed_nh_ratio': 32, 'ff_hd': 256, 'classifier_hd': 256, 'dropout': 0.35021205012788076, 'lr': 0.0005065891753204239, 'weight_decay': 0.0020082625858642666, 'batch_size': 320, 'patience': 25, 'epochs': 75, 'use_augmentation': True, 'aug_probability': 0.47485890889119553, 'prob': 0.39689049271513777, 'noise_std': 0.22806525426799784, 'dropout_aug': 0.060496713349365155, 'alpha': 0.21231406957841936, 'from_unsupervised': True, 'pretrain_epochs': 55}. Best is trial 18 with value: 0.9591860315412027.
Fold 1 finished with balanced_accuracy value = 0.948547
Fold 2 finished with balanced_accuracy value = 0.958435
Fold 3 finished with balanced_accuracy value = 0.957814
[I 2026-01-28 16:59:52,746] Trial 61 pruned.
Fold 1 finished with balanced_accuracy value = 0.950243
Fold 2 finished with balanced_accuracy value = 0.955859
Fold 3 finished with balanced_accuracy value = 0.956763
[I 2026-01-28 17:08:15,332] Trial 62 pruned.
Fold 1 finished with balanced_accuracy value = 0.953593
Fold 2 finished with balanced_accuracy value = 0.955855
Fold 3 finished with balanced_accuracy value = 0.957612
[I 2026-01-28 17:10:16,921] Trial 63 pruned.
Fold 1 finished with balanced_accuracy value = 0.952128
Fold 2 finished with balanced_accuracy value = 0.964337
Fold 3 finished with balanced_accuracy value = 0.954693
[I 2026-01-28 17:15:50,237] Trial 64 pruned.
Fold 1 finished with balanced_accuracy value = 0.953956
Fold 2 finished with balanced_accuracy value = 0.955247
Fold 3 finished with balanced_accuracy value = 0.956433
[I 2026-01-28 17:21:51,580] Trial 65 pruned.
Fold 1 finished with balanced_accuracy value = 0.946474
[I 2026-01-28 17:22:46,640] Trial 66 pruned.
Fold 1 finished with balanced_accuracy value = 0.947861
[I 2026-01-28 17:23:56,768] Trial 67 pruned.
Fold 1 finished with balanced_accuracy value = 0.955116
Fold 2 finished with balanced_accuracy value = 0.953555
Fold 3 finished with balanced_accuracy value = 0.949442
[I 2026-01-28 17:25:28,762] Trial 68 pruned.
Fold 1 finished with balanced_accuracy value = 0.949812
[I 2026-01-28 17:27:09,894] Trial 69 pruned.
Fold 1 finished with balanced_accuracy value = 0.944974
Fold 2 finished with balanced_accuracy value = 0.955020
Fold 3 finished with balanced_accuracy value = 0.955819
[I 2026-01-28 17:28:17,438] Trial 70 pruned.
Fold 1 finished with balanced_accuracy value = 0.952038
Fold 2 finished with balanced_accuracy value = 0.958888
Fold 3 finished with balanced_accuracy value = 0.957512
[I 2026-01-28 17:36:09,372] Trial 71 pruned.
Fold 1 finished with balanced_accuracy value = 0.953227
Fold 2 finished with balanced_accuracy value = 0.958105
Fold 3 finished with balanced_accuracy value = 0.955025
[I 2026-01-28 17:44:31,466] Trial 72 pruned.
Fold 1 finished with balanced_accuracy value = 0.957138
Fold 2 finished with balanced_accuracy value = 0.964818
Fold 3 finished with balanced_accuracy value = 0.960417
Fold 4 finished with balanced_accuracy value = 0.953444
Fold 5 finished with balanced_accuracy value = 0.966667
[I 2026-01-28 17:57:13,759] Trial 73 finished with value: 0.9604968544328655 and parameters: {'nc': 16, 'nb': 5, 'nh': 16, 'ed_nh_ratio': 32, 'ff_hd': 128, 'classifier_hd': 256, 'dropout': 0.3462299357848513, 'lr': 0.0002640372041586079, 'weight_decay': 0.006082974465326182, 'batch_size': 192, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.3997306970107156, 'prob': 0.390336598814089, 'noise_std': 0.21822764707701792, 'dropout_aug': 0.05883115391561408, 'alpha': 0.23709798412205382, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 73 with value: 0.9604968544328655.
Fold 1 finished with balanced_accuracy value = 0.956959
Fold 2 finished with balanced_accuracy value = 0.959447
Fold 3 finished with balanced_accuracy value = 0.956299
[I 2026-01-28 18:01:56,529] Trial 74 pruned.
Fold 1 finished with balanced_accuracy value = 0.948410
[I 2026-01-28 18:04:32,295] Trial 75 pruned.
Fold 1 finished with balanced_accuracy value = 0.954374
Fold 2 finished with balanced_accuracy value = 0.963027
Fold 3 finished with balanced_accuracy value = 0.958676
Fold 4 finished with balanced_accuracy value = 0.964568
Fold 5 finished with balanced_accuracy value = 0.962537
[I 2026-01-28 18:16:05,558] Trial 76 finished with value: 0.9606364433939255 and parameters: {'nc': 14, 'nb': 5, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 1024, 'classifier_hd': 128, 'dropout': 0.3336215826165275, 'lr': 0.00033569666986235034, 'weight_decay': 0.007179214437325918, 'batch_size': 256, 'patience': 30, 'epochs': 140, 'use_augmentation': True, 'aug_probability': 0.31297654610450926, 'prob': 0.38672014324763565, 'noise_std': 0.21295604898664128, 'dropout_aug': 0.09005150753262134, 'alpha': 0.21736849373462216, 'from_unsupervised': True, 'pretrain_epochs': 45}. Best is trial 76 with value: 0.9606364433939255.
Fold 1 finished with balanced_accuracy value = 0.952988
Fold 2 finished with balanced_accuracy value = 0.959585
Fold 3 finished with balanced_accuracy value = 0.955431
[I 2026-01-28 18:21:45,753] Trial 77 pruned.
Fold 1 finished with balanced_accuracy value = 0.952359
Fold 2 finished with balanced_accuracy value = 0.959303
Fold 3 finished with balanced_accuracy value = 0.953271
[I 2026-01-28 18:27:23,249] Trial 78 pruned.
Fold 1 finished with balanced_accuracy value = 0.948629
[I 2026-01-28 18:29:30,930] Trial 79 pruned.
Fold 1 finished with balanced_accuracy value = 0.961894
Fold 2 finished with balanced_accuracy value = 0.962188
Fold 3 finished with balanced_accuracy value = 0.963513
Fold 4 finished with balanced_accuracy value = 0.964275
Fold 5 finished with balanced_accuracy value = 0.964814
[I 2026-01-28 18:46:49,251] Trial 80 finished with value: 0.9633366574360365 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.28474826541977516, 'lr': 0.00037501881788009933, 'weight_decay': 0.0012840146526438892, 'batch_size': 64, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.32710110382050156, 'prob': 0.38707592245987854, 'noise_std': 0.18431311014306132, 'dropout_aug': 0.15021695120945378, 'alpha': 0.21844009169174042, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 80 with value: 0.9633366574360365.
Fold 1 finished with balanced_accuracy value = 0.956618
Fold 2 finished with balanced_accuracy value = 0.963365
Fold 3 finished with balanced_accuracy value = 0.963342
Fold 4 finished with balanced_accuracy value = 0.961615
Fold 5 finished with balanced_accuracy value = 0.967051
[I 2026-01-28 19:04:34,010] Trial 81 finished with value: 0.9623982033162651 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.3224424988406104, 'lr': 0.00024892577339734843, 'weight_decay': 0.001394181720932432, 'batch_size': 64, 'patience': 30, 'epochs': 95, 'use_augmentation': True, 'aug_probability': 0.32425445826146126, 'prob': 0.3837764530001343, 'noise_std': 0.1884869374341621, 'dropout_aug': 0.1404160092745467, 'alpha': 0.22093070168582357, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 80 with value: 0.9633366574360365.
Fold 1 finished with balanced_accuracy value = 0.958029
Fold 2 finished with balanced_accuracy value = 0.963428
Fold 3 finished with balanced_accuracy value = 0.962400
Fold 4 finished with balanced_accuracy value = 0.964562
Fold 5 finished with balanced_accuracy value = 0.968108
[I 2026-01-28 19:25:19,227] Trial 82 finished with value: 0.9633053926615478 and parameters: {'nc': 14, 'nb': 5, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.32120909178209384, 'lr': 0.0003762947072894607, 'weight_decay': 0.0026076765209491286, 'batch_size': 64, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.29644241314446246, 'prob': 0.3875376933331931, 'noise_std': 0.18425020283147336, 'dropout_aug': 0.14420424422261968, 'alpha': 0.21723651105427144, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 80 with value: 0.9633366574360365.
Fold 1 finished with balanced_accuracy value = 0.958590
Fold 2 finished with balanced_accuracy value = 0.965439
Fold 3 finished with balanced_accuracy value = 0.962000
Fold 4 finished with balanced_accuracy value = 0.959763
Fold 5 finished with balanced_accuracy value = 0.966709
[I 2026-01-28 19:43:00,394] Trial 83 finished with value: 0.9625001048519299 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.3236386579157021, 'lr': 0.0003524397148422823, 'weight_decay': 0.0014538509485592789, 'batch_size': 64, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.28985954416386234, 'prob': 0.39095219780542556, 'noise_std': 0.18261650046048034, 'dropout_aug': 0.13690323658646905, 'alpha': 0.2014174020978101, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 80 with value: 0.9633366574360365.
Fold 1 finished with balanced_accuracy value = 0.956811
Fold 2 finished with balanced_accuracy value = 0.966141
Fold 3 finished with balanced_accuracy value = 0.960946
Fold 4 finished with balanced_accuracy value = 0.967771
Fold 5 finished with balanced_accuracy value = 0.965353
[I 2026-01-28 20:03:55,635] Trial 84 finished with value: 0.963404217200494 and parameters: {'nc': 14, 'nb': 5, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.28427928253470397, 'lr': 0.0003774561158554304, 'weight_decay': 0.0012718353972020165, 'batch_size': 64, 'patience': 30, 'epochs': 85, 'use_augmentation': True, 'aug_probability': 0.29401826139834386, 'prob': 0.38779029271526183, 'noise_std': 0.18302507412696095, 'dropout_aug': 0.1396373185216216, 'alpha': 0.20042214467630054, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.955944
Fold 2 finished with balanced_accuracy value = 0.965554
Fold 3 finished with balanced_accuracy value = 0.960090
Fold 4 finished with balanced_accuracy value = 0.966415
Fold 5 finished with balanced_accuracy value = 0.965903
[I 2026-01-28 20:23:00,747] Trial 85 finished with value: 0.9627813860517641 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.28053790895868774, 'lr': 0.00037578924889930364, 'weight_decay': 0.001372800011915178, 'batch_size': 64, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.281878072579209, 'prob': 0.3906273650963675, 'noise_std': 0.18483817219577758, 'dropout_aug': 0.13378182050228363, 'alpha': 0.19270906574214192, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.958009
Fold 2 finished with balanced_accuracy value = 0.964692
Fold 3 finished with balanced_accuracy value = 0.962194
Fold 4 finished with balanced_accuracy value = 0.961490
Fold 5 finished with balanced_accuracy value = 0.968336
[I 2026-01-28 20:41:31,575] Trial 86 finished with value: 0.9629442070247982 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 896, 'classifier_hd': 128, 'dropout': 0.28399364906364377, 'lr': 0.0003618615940090217, 'weight_decay': 0.00984987483827845, 'batch_size': 64, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.2965028812441154, 'prob': 0.38788043913262893, 'noise_std': 0.191185433636686, 'dropout_aug': 0.15083348228043086, 'alpha': 0.19987149621330183, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.958594
Fold 2 finished with balanced_accuracy value = 0.964117
Fold 3 finished with balanced_accuracy value = 0.962030
Fold 4 finished with balanced_accuracy value = 0.960820
Fold 5 finished with balanced_accuracy value = 0.964444
[I 2026-01-28 20:59:40,674] Trial 87 finished with value: 0.9620008579852704 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 896, 'classifier_hd': 128, 'dropout': 0.27745674112032614, 'lr': 0.00036602004159907677, 'weight_decay': 0.0013942299307122114, 'batch_size': 64, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.30108711612351907, 'prob': 0.3886382978380228, 'noise_std': 0.18680478165579276, 'dropout_aug': 0.19175848957867997, 'alpha': 0.20295727611876438, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.957986
Fold 2 finished with balanced_accuracy value = 0.964468
Fold 3 finished with balanced_accuracy value = 0.961674
Fold 4 finished with balanced_accuracy value = 0.962949
Fold 5 finished with balanced_accuracy value = 0.968933
[I 2026-01-28 21:18:43,113] Trial 88 finished with value: 0.9632018225500438 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 896, 'classifier_hd': 128, 'dropout': 0.28140084594243797, 'lr': 0.0003855786468682377, 'weight_decay': 0.0014039886797510028, 'batch_size': 64, 'patience': 30, 'epochs': 75, 'use_augmentation': True, 'aug_probability': 0.29736199633178567, 'prob': 0.3867969532311257, 'noise_std': 0.1867852562573935, 'dropout_aug': 0.1979891287252411, 'alpha': 0.15527788858860403, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.949339
[I 2026-01-28 21:21:14,139] Trial 89 pruned.
Fold 1 finished with balanced_accuracy value = 0.953380
Fold 2 finished with balanced_accuracy value = 0.962868
Fold 3 finished with balanced_accuracy value = 0.962329
Fold 4 finished with balanced_accuracy value = 0.959069
Fold 5 finished with balanced_accuracy value = 0.963113
[I 2026-01-28 21:39:32,441] Trial 90 finished with value: 0.9601519819318114 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 896, 'classifier_hd': 128, 'dropout': 0.28396945184873784, 'lr': 0.0007098504216374458, 'weight_decay': 0.0015627853990847107, 'batch_size': 64, 'patience': 30, 'epochs': 70, 'use_augmentation': True, 'aug_probability': 0.23864859208329253, 'prob': 0.37799704628699393, 'noise_std': 0.1914210921205724, 'dropout_aug': 0.18807193828535562, 'alpha': 0.20122727475695887, 'from_unsupervised': True, 'pretrain_epochs': 55}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.957967
Fold 2 finished with balanced_accuracy value = 0.961885
Fold 3 finished with balanced_accuracy value = 0.960770
Fold 4 finished with balanced_accuracy value = 0.958455
Fold 5 finished with balanced_accuracy value = 0.961536
[I 2026-01-28 21:50:54,310] Trial 91 finished with value: 0.9601227087794747 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.28349355125906234, 'lr': 0.00036418224121532577, 'weight_decay': 0.009638926626844742, 'batch_size': 128, 'patience': 30, 'epochs': 80, 'use_augmentation': True, 'aug_probability': 0.2973353314579681, 'prob': 0.38614161314333184, 'noise_std': 0.16073028194673633, 'dropout_aug': 0.2360238640040561, 'alpha': 0.18843781307312932, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.954662
Fold 2 finished with balanced_accuracy value = 0.965720
Fold 3 finished with balanced_accuracy value = 0.963980
Fold 4 finished with balanced_accuracy value = 0.960153
Fold 5 finished with balanced_accuracy value = 0.967513
[I 2026-01-28 22:10:34,087] Trial 92 finished with value: 0.962405503987808 and parameters: {'nc': 14, 'nb': 4, 'nh': 14, 'ed_nh_ratio': 28, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.3162445737686785, 'lr': 0.0004786367641525902, 'weight_decay': 0.0006489570406783776, 'batch_size': 64, 'patience': 30, 'epochs': 85, 'use_augmentation': True, 'aug_probability': 0.2962927784557955, 'prob': 0.39169080186597643, 'noise_std': 0.17976858157741263, 'dropout_aug': 0.16659175016919034, 'alpha': 0.1672404480658238, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.955715
Fold 2 finished with balanced_accuracy value = 0.967120
Fold 3 finished with balanced_accuracy value = 0.960169
[I 2026-01-28 22:20:32,519] Trial 93 pruned.
Fold 1 finished with balanced_accuracy value = 0.957351
Fold 2 finished with balanced_accuracy value = 0.962107
Fold 3 finished with balanced_accuracy value = 0.960967
Fold 4 finished with balanced_accuracy value = 0.961511
Fold 5 finished with balanced_accuracy value = 0.969004
[I 2026-01-28 22:32:54,236] Trial 94 finished with value: 0.9621880490094551 and parameters: {'nc': 14, 'nb': 4, 'nh': 12, 'ed_nh_ratio': 28, 'ff_hd': 896, 'classifier_hd': 128, 'dropout': 0.3083773715283699, 'lr': 0.0005194795473953223, 'weight_decay': 0.0029044933465324054, 'batch_size': 128, 'patience': 30, 'epochs': 70, 'use_augmentation': True, 'aug_probability': 0.28623125212776257, 'prob': 0.3595473668357951, 'noise_std': 0.19201019134645325, 'dropout_aug': 0.16578062543115515, 'alpha': 0.15969156566856696, 'from_unsupervised': True, 'pretrain_epochs': 50}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.956330
Fold 2 finished with balanced_accuracy value = 0.967496
Fold 3 finished with balanced_accuracy value = 0.959352
Fold 4 finished with balanced_accuracy value = 0.961692
Fold 5 finished with balanced_accuracy value = 0.968904
[I 2026-01-28 22:43:40,051] Trial 95 finished with value: 0.9627548754477251 and parameters: {'nc': 14, 'nb': 4, 'nh': 12, 'ed_nh_ratio': 24, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.30487234872676605, 'lr': 0.0006716329301100903, 'weight_decay': 0.00293089751546688, 'batch_size': 128, 'patience': 30, 'epochs': 70, 'use_augmentation': True, 'aug_probability': 0.2766248929639144, 'prob': 0.36033228566689324, 'noise_std': 0.19688464356458957, 'dropout_aug': 0.14980826533719238, 'alpha': 0.15486168132927555, 'from_unsupervised': True, 'pretrain_epochs': 55}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.958383
Fold 2 finished with balanced_accuracy value = 0.961873
Fold 3 finished with balanced_accuracy value = 0.963134
Fold 4 finished with balanced_accuracy value = 0.960468
Fold 5 finished with balanced_accuracy value = 0.967169
[I 2026-01-28 23:02:10,653] Trial 96 finished with value: 0.9622054626542894 and parameters: {'nc': 14, 'nb': 4, 'nh': 12, 'ed_nh_ratio': 24, 'ff_hd': 768, 'classifier_hd': 128, 'dropout': 0.3207003241609475, 'lr': 0.0004450315661657244, 'weight_decay': 0.001563399369245296, 'batch_size': 64, 'patience': 30, 'epochs': 75, 'use_augmentation': True, 'aug_probability': 0.33355979303118954, 'prob': 0.34591544192013, 'noise_std': 0.14602740950632725, 'dropout_aug': 0.15301981457143077, 'alpha': 0.11052312136471357, 'from_unsupervised': True, 'pretrain_epochs': 55}. Best is trial 84 with value: 0.963404217200494.
Fold 1 finished with balanced_accuracy value = 0.954928
Fold 2 finished with balanced_accuracy value = 0.953139
Fold 3 finished with balanced_accuracy value = 0.958629
[I 2026-01-28 23:08:33,365] Trial 97 pruned.
Fold 1 finished with balanced_accuracy value = 0.955282
Fold 2 finished with balanced_accuracy value = 0.962926
Fold 3 finished with balanced_accuracy value = 0.959445
[I 2026-01-28 23:16:53,068] Trial 98 pruned.
Fold 1 finished with balanced_accuracy value = 0.955228
Fold 2 finished with balanced_accuracy value = 0.962418
Fold 3 finished with balanced_accuracy value = 0.952276
[I 2026-01-28 23:20:22,040] Trial 99 pruned.
Best value (balanced_accuracy) = 0.963404217200494
Best hyperparameters saved to: model_scadam_hp_tune/best_params.txt
[21]:
{'nc': 14,
'nb': 5,
'nh': 14,
'ed_nh_ratio': 28,
'ff_hd': 768,
'classifier_hd': 128,
'dropout': 0.28427928253470397,
'lr': 0.0003774561158554304,
'weight_decay': 0.0012718353972020165,
'batch_size': 64,
'patience': 30,
'epochs': 85,
'use_augmentation': True,
'aug_probability': 0.29401826139834386,
'prob': 0.38779029271526183,
'noise_std': 0.18302507412696095,
'dropout_aug': 0.1396373185216216,
'alpha': 0.20042214467630054,
'from_unsupervised': True,
'pretrain_epochs': 50}
[23]:
# Train model using optimal parameters from model_scadam_hp_tune folder
scparadise.scadam.train_tuned(
adata_train_1,
path='', # path to save model
path_tuned='model_scadam_hp_tune', # path to a folder with tuned hyperparameters
model_name='model_scadam_tuned', # folder name with model
celltype_keys=['cell_type'],
eval_metric=['accuracy', 'balanced_accuracy']
)
Successfully loaded tuned hyperparameters!
Device: cuda
Number of features: 1200
Label hierarchy: cell_type
Annotation levels weights using strategy 'linear_offset':
cell_type: 15 cell types, 1.0 relative weight
Dataset split:
Train dataset contains: 13738 cells, it is 80.0 % of input dataset
Validation dataset contains: 3435 cells, it is 20.0 % of input dataset
Unsupervised pretraining: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [02:59<00:00, 3.59s/it]
Training scAdam model: 74%|█████████████████████████████████████████████████████████████████████████████████▌ | 63/85 [02:56<01:01, 2.81s/it]
Early stopping triggered! Best score: 0.9687
Training completed!
Fitting unknown cells detector
UnknownCellDetector fitted successfully!
Model saved to model_scadam_tuned
[30]:
# Predict cell types using trained model
adata_test = scparadise.scadam.predict(
adata_test,
path_model = 'model_scadam_tuned'
)
scAdam model with unknown detector loaded from model_scadam_tuned
Gene alignment:
Model features: 1200
Matched features: 1200 (100.0%)
Predicting: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 72/72 [00:00<00:00, 108.27it/s]
Added cell type column: pred_celltype_l1
Added probabilities column: pred_celltype_l1_probability
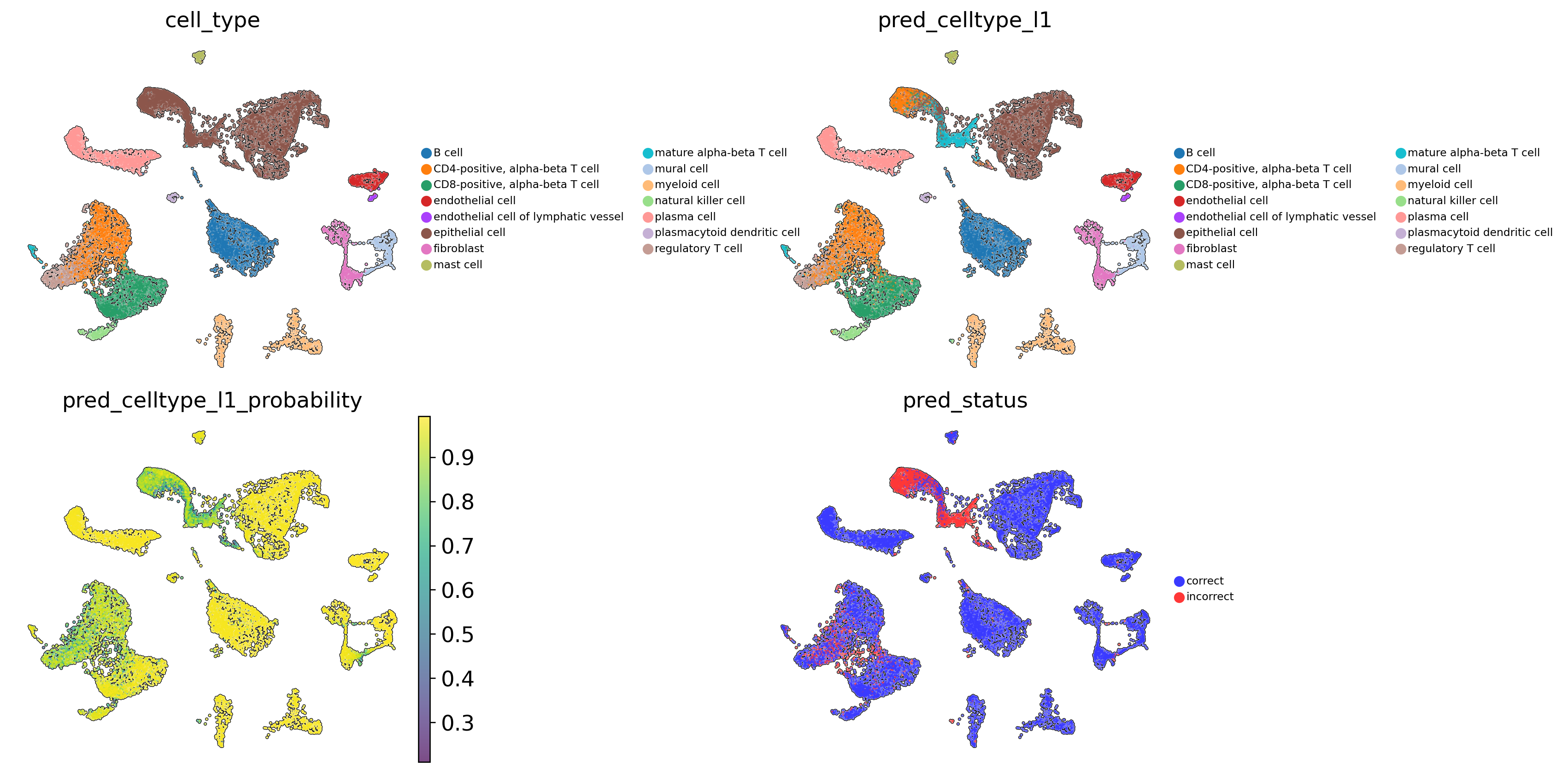
Evaluation of prediction results#
Hyperparameters tuning leads to an increase in the model’s overall accuracy (+2.3%) and balanced accuracy (+1.38%).
Below are examples of improved model performance for certain cell types.
CD4-positive, alpha-beta T cell(precision - 0.3884 vs 0.3068)endothelial cell of lymphatic vessel(sensitivity - 0.9615 vs 0.8462)epithelial cell(sensitivity - 0.5434 vs 0.4803)mature alpha-beta T cell(sensitivity - 0.9467 vs 0.8667)natural killer cell(sensitivity - 0.9641 vs 0.8969)regulatory T cell(precision - 0.5832 vs 0.4664)
However, a decrease in prediction accuracy may be observed for some cell types.
regulatory T cell(sensitivity - 0.6589 vs 0.7901)natural killer cell(precision - 0.7465 vs 0.8811)
[31]:
## Check model quality
df_hp_tuned = scparadise.scnoah.report_classif_full(
adata_test,
celltype='cell_type',
pred_celltype='pred_celltype_l1'
)
df_hp_tuned
[31]:
| precision | recall/sensitivity | specificity | f1-score | geometric mean | index balanced accuracy | number of cells | |
|---|---|---|---|---|---|---|---|
| B cell | 0.9557 | 0.979 | 0.9943 | 0.9672 | 0.9866 | 0.9719 | 2050 |
| CD4-positive, alpha-beta T cell | 0.3884 | 0.8604 | 0.8743 | 0.5352 | 0.8673 | 0.7512 | 1554 |
| CD8-positive, alpha-beta T cell | 0.8307 | 0.9013 | 0.9807 | 0.8645 | 0.9401 | 0.8768 | 1742 |
| endothelial cell | 0.9956 | 0.9912 | 0.9999 | 0.9934 | 0.9956 | 0.9903 | 457 |
| endothelial cell of lymphatic vessel | 1.0000 | 0.9615 | 1.0 | 0.9804 | 0.9806 | 0.9578 | 52 |
| epithelial cell | 0.9966 | 0.5434 | 0.9987 | 0.7033 | 0.7367 | 0.518 | 7505 |
| fibroblast | 0.9501 | 0.9852 | 0.998 | 0.9673 | 0.9916 | 0.982 | 676 |
| mast cell | 0.9928 | 0.9324 | 0.9999 | 0.9617 | 0.9656 | 0.9261 | 148 |
| mature alpha-beta T cell | 0.0604 | 0.9467 | 0.9394 | 0.1136 | 0.943 | 0.89 | 75 |
| mural cell | 0.9552 | 0.9748 | 0.9989 | 0.9649 | 0.9868 | 0.9714 | 437 |
| myeloid cell | 0.9862 | 0.9848 | 0.9994 | 0.9855 | 0.9921 | 0.9829 | 726 |
| natural killer cell | 0.7465 | 0.9641 | 0.996 | 0.8415 | 0.9799 | 0.9572 | 223 |
| plasma cell | 0.9706 | 0.9969 | 0.9965 | 0.9835 | 0.9967 | 0.9934 | 1919 |
| plasmacytoid dendritic cell | 0.9608 | 0.98 | 0.9999 | 0.9703 | 0.9899 | 0.9779 | 50 |
| regulatory T cell | 0.5832 | 0.6589 | 0.9817 | 0.6188 | 0.8042 | 0.6259 | 686 |
| macro avg | 0.8249 | 0.9107 | 0.9838 | 0.8301 | 0.9438 | 0.8915 | |
| weighted avg | 0.8962 | 0.7727 | 0.9848 | 0.7975 | 0.864 | 0.7476 | |
| Accuracy | 0.7727 | ||||||
| Balanced accuracy | 0.9107 |
[32]:
# Order cell type colors
celltype = np.unique(adata_test.obs['cell_type']).tolist()
adata_test.obs['cell_type'] = pd.Categorical(
values=adata_test.obs['cell_type'], categories=celltype, ordered=True
)
adata_test.obs['pred_celltype_l1'] = pd.Categorical(
values=adata_test.obs['pred_celltype_l1'], categories=celltype, ordered=True
)
# Add prediction status. Label cells as correct or incorrect based on the comparison between ground truth cell types and predictions.
scparadise.scnoah.pred_status(adata_test, celltype='cell_type', pred_celltype='pred_celltype_l1')
[33]:
# Visualise predicted cell types levels, prediction probabilities and prediction status
sc.pl.umap(
adata_test,
color=[
'cell_type',
'pred_celltype_l1',
'pred_celltype_l1_probability',
'pred_status'
],
frameon = False,
add_outline = True,
legend_loc = 'right margin',
legend_fontsize = 7,
legend_fontoutline = 1,
ncols=2,
wspace = 0.7,
hspace = 0.1
)
[34]:
# Compare prediction results
# 'untuned' row represents untuned model
# 'hp tuned' row represents tuned model
df.compare(df_hp_tuned, keep_equal=True, align_axis = 0, result_names=('untuned', 'hp tuned'))
[34]:
| precision | recall/sensitivity | specificity | f1-score | geometric mean | index balanced accuracy | ||
|---|---|---|---|---|---|---|---|
| B cell | untuned | 0.9467 | 0.98 | 0.993 | 0.9631 | 0.9865 | 0.9719 |
| hp tuned | 0.9557 | 0.979 | 0.9943 | 0.9672 | 0.9866 | 0.9719 | |
| CD4-positive, alpha-beta T cell | untuned | 0.3068 | 0.8295 | 0.826 | 0.4479 | 0.8278 | 0.6854 |
| hp tuned | 0.3884 | 0.8604 | 0.8743 | 0.5352 | 0.8673 | 0.7512 | |
| CD8-positive, alpha-beta T cell | untuned | 0.8736 | 0.9248 | 0.9859 | 0.8985 | 0.9549 | 0.9062 |
| hp tuned | 0.8307 | 0.9013 | 0.9807 | 0.8645 | 0.9401 | 0.8768 | |
| endothelial cell | untuned | 0.9870 | 0.9956 | 0.9997 | 0.9913 | 0.9976 | 0.9949 |
| hp tuned | 0.9956 | 0.9912 | 0.9999 | 0.9934 | 0.9956 | 0.9903 | |
| endothelial cell of lymphatic vessel | untuned | 1.0000 | 0.8462 | 1.0 | 0.9167 | 0.9199 | 0.8331 |
| hp tuned | 1.0000 | 0.9615 | 1.0 | 0.9804 | 0.9806 | 0.9578 | |
| epithelial cell | untuned | 0.9953 | 0.4803 | 0.9984 | 0.648 | 0.6925 | 0.4547 |
| hp tuned | 0.9966 | 0.5434 | 0.9987 | 0.7033 | 0.7367 | 0.518 | |
| fibroblast | untuned | 0.9736 | 0.9837 | 0.999 | 0.9787 | 0.9913 | 0.9812 |
| hp tuned | 0.9501 | 0.9852 | 0.998 | 0.9673 | 0.9916 | 0.982 | |
| mast cell | untuned | 0.9861 | 0.9595 | 0.9999 | 0.9726 | 0.9795 | 0.9555 |
| hp tuned | 0.9928 | 0.9324 | 0.9999 | 0.9617 | 0.9656 | 0.9261 | |
| mature alpha-beta T cell | untuned | 0.1017 | 0.8667 | 0.9685 | 0.1821 | 0.9162 | 0.8308 |
| hp tuned | 0.0604 | 0.9467 | 0.9394 | 0.1136 | 0.943 | 0.89 | |
| mural cell | untuned | 0.9724 | 0.9657 | 0.9993 | 0.969 | 0.9824 | 0.9618 |
| hp tuned | 0.9552 | 0.9748 | 0.9989 | 0.9649 | 0.9868 | 0.9714 | |
| myeloid cell | untuned | 0.9902 | 0.9766 | 0.9996 | 0.9834 | 0.988 | 0.9739 |
| hp tuned | 0.9862 | 0.9848 | 0.9994 | 0.9855 | 0.9921 | 0.9829 | |
| natural killer cell | untuned | 0.8811 | 0.8969 | 0.9985 | 0.8889 | 0.9463 | 0.8864 |
| hp tuned | 0.7465 | 0.9641 | 0.996 | 0.8415 | 0.9799 | 0.9572 | |
| plasma cell | untuned | 0.9825 | 0.9974 | 0.9979 | 0.9899 | 0.9977 | 0.9953 |
| hp tuned | 0.9706 | 0.9969 | 0.9965 | 0.9835 | 0.9967 | 0.9934 | |
| plasmacytoid dendritic cell | untuned | 0.9231 | 0.96 | 0.9998 | 0.9412 | 0.9797 | 0.956 |
| hp tuned | 0.9608 | 0.98 | 0.9999 | 0.9703 | 0.9899 | 0.9779 | |
| regulatory T cell | untuned | 0.4664 | 0.7901 | 0.9648 | 0.5866 | 0.8731 | 0.749 |
| hp tuned | 0.5832 | 0.6589 | 0.9817 | 0.6188 | 0.8042 | 0.6259 | |
| macro avg | untuned | 0.8258 | 0.8969 | 0.982 | 0.8238 | 0.9356 | 0.8757 |
| hp tuned | 0.8249 | 0.9107 | 0.9838 | 0.8301 | 0.9438 | 0.8915 | |
| weighted avg | untuned | 0.8916 | 0.7497 | 0.9807 | 0.7707 | 0.8457 | 0.7219 |
| hp tuned | 0.8962 | 0.7727 | 0.9848 | 0.7975 | 0.864 | 0.7476 | |
| Accuracy | untuned | 0.7497 | |||||
| hp tuned | 0.7727 | ||||||
| Balanced accuracy | untuned | 0.8969 | |||||
| hp tuned | 0.9107 |
[35]:
# Compare prediction results
# 'warm start' row represents warm start trained model
# 'hp tuned' row represents tuned model
df_warm_start.compare(df_hp_tuned, keep_equal=True, align_axis = 0, result_names=('warm start', 'hp tuned'))
[35]:
| precision | recall/sensitivity | specificity | f1-score | geometric mean | index balanced accuracy | ||
|---|---|---|---|---|---|---|---|
| B cell | warm start | 0.9901 | 0.9776 | 0.9988 | 0.9838 | 0.9881 | 0.9743 |
| hp tuned | 0.9557 | 0.979 | 0.9943 | 0.9672 | 0.9866 | 0.9719 | |
| CD4-positive, alpha-beta T cell | warm start | 0.8621 | 0.861 | 0.9872 | 0.8616 | 0.922 | 0.8393 |
| hp tuned | 0.3884 | 0.8604 | 0.8743 | 0.5352 | 0.8673 | 0.7512 | |
| CD8-positive, alpha-beta T cell | warm start | 0.9274 | 0.9099 | 0.9925 | 0.9186 | 0.9503 | 0.8956 |
| hp tuned | 0.8307 | 0.9013 | 0.9807 | 0.8645 | 0.9401 | 0.8768 | |
| endothelial cell | warm start | 0.9978 | 0.9978 | 0.9999 | 0.9978 | 0.9989 | 0.9975 |
| hp tuned | 0.9956 | 0.9912 | 0.9999 | 0.9934 | 0.9956 | 0.9903 | |
| endothelial cell of lymphatic vessel | warm start | 1.0000 | 0.9808 | 1.0 | 0.9903 | 0.9903 | 0.9789 |
| hp tuned | 1.0000 | 0.9615 | 1.0 | 0.9804 | 0.9806 | 0.9578 | |
| epithelial cell | warm start | 0.9928 | 0.9861 | 0.995 | 0.9894 | 0.9906 | 0.9803 |
| hp tuned | 0.9966 | 0.5434 | 0.9987 | 0.7033 | 0.7367 | 0.518 | |
| fibroblast | warm start | 0.9881 | 0.9793 | 0.9995 | 0.9837 | 0.9894 | 0.9769 |
| hp tuned | 0.9501 | 0.9852 | 0.998 | 0.9673 | 0.9916 | 0.982 | |
| mast cell | warm start | 0.9797 | 0.9797 | 0.9998 | 0.9797 | 0.9897 | 0.9776 |
| hp tuned | 0.9928 | 0.9324 | 0.9999 | 0.9617 | 0.9656 | 0.9261 | |
| mature alpha-beta T cell | warm start | 0.8375 | 0.8933 | 0.9993 | 0.8645 | 0.9448 | 0.8832 |
| hp tuned | 0.0604 | 0.9467 | 0.9394 | 0.1136 | 0.943 | 0.89 | |
| mural cell | warm start | 0.9515 | 0.9886 | 0.9988 | 0.9697 | 0.9937 | 0.9863 |
| hp tuned | 0.9552 | 0.9748 | 0.9989 | 0.9649 | 0.9868 | 0.9714 | |
| myeloid cell | warm start | 0.9875 | 0.9793 | 0.9995 | 0.9834 | 0.9894 | 0.9769 |
| hp tuned | 0.9862 | 0.9848 | 0.9994 | 0.9855 | 0.9921 | 0.9829 | |
| natural killer cell | warm start | 0.7553 | 0.9552 | 0.9962 | 0.8436 | 0.9755 | 0.9476 |
| hp tuned | 0.7465 | 0.9641 | 0.996 | 0.8415 | 0.9799 | 0.9572 | |
| plasma cell | warm start | 0.9876 | 0.9953 | 0.9985 | 0.9914 | 0.9969 | 0.9935 |
| hp tuned | 0.9706 | 0.9969 | 0.9965 | 0.9835 | 0.9967 | 0.9934 | |
| regulatory T cell | warm start | 0.7447 | 0.7741 | 0.9897 | 0.7591 | 0.8752 | 0.7495 |
| hp tuned | 0.5832 | 0.6589 | 0.9817 | 0.6188 | 0.8042 | 0.6259 | |
| macro avg | warm start | 0.9309 | 0.9492 | 0.997 | 0.9391 | 0.9723 | 0.9424 |
| hp tuned | 0.8249 | 0.9107 | 0.9838 | 0.8301 | 0.9438 | 0.8915 | |
| weighted avg | warm start | 0.9604 | 0.9593 | 0.9954 | 0.9596 | 0.9768 | 0.9518 |
| hp tuned | 0.8962 | 0.7727 | 0.9848 | 0.7975 | 0.864 | 0.7476 | |
| Accuracy | warm start | 0.9593 | |||||
| hp tuned | 0.7727 | ||||||
| Balanced accuracy | warm start | 0.9492 | |||||
| hp tuned | 0.9107 |
Recommendation#
We recommend warm start training instead of hyperparameter tuning if possible. However, in the absence of an additional training dataset, hyperparameter tuning may help improve model performance.
[36]:
import session_info
session_info.show()
[36]:
Click to view session information
----- anndata 0.11.4 matplotlib 3.10.6 numpy 1.26.4 pandas 2.3.3 scanpy 1.11.4 scparadise 1.0.0 session_info v1.0.1 -----
Click to view modules imported as dependencies
PIL 11.3.0 alembic 1.16.5 anyio NA arrow 1.3.0 asttokens NA attr 25.3.0 attrs 25.3.0 babel 2.17.0 backports NA certifi 2025.08.03 cffi 1.17.1 charset_normalizer 3.4.3 cloudpickle 3.1.1 colorlog NA comm 0.2.3 cupy 13.6.0 cupy_backends NA cupyx NA cycler 0.12.1 cython_runtime NA dask 2025.10.0 dateutil 2.9.0.post0 debugpy 1.8.16 decorator 5.2.1 defusedxml 0.7.1 exceptiongroup 1.3.0 executing 2.2.1 fastjsonschema NA fastrlock 0.8.3 fqdn NA fsspec 2025.7.0 greenlet 3.2.4 h5py 3.14.0 idna 3.10 igraph 0.11.9 imblearn 0.14.0 importlib_metadata NA ipykernel 6.30.1 ipywidgets 8.1.8 isoduration NA jaraco NA jedi 0.19.2 jinja2 3.1.6 joblib 1.5.2 json5 0.12.1 jsonpointer 3.0.0 jsonschema 4.25.1 jsonschema_specifications NA jupyter_events 0.12.0 jupyter_server 2.17.0 jupyterlab_server 2.28.0 kiwisolver 1.4.9 lark 1.2.2 lazy_loader 0.4 legacy_api_wrap NA leidenalg 0.10.2 llvmlite 0.44.0 louvain 0.8.2 mako 1.3.10 markupsafe 3.0.2 matplotlib_inline 0.1.7 more_itertools 10.3.0 mpl_toolkits NA mpmath 1.3.0 mudata 0.3.2 muon 0.1.7 natsort 8.4.0 nbformat 5.10.4 numba 0.61.2 numexpr 2.14.1 optuna 4.5.0 overrides NA packaging 25.0 parso 0.8.5 patsy 1.0.1 pkg_resources NA platformdirs 4.4.0 plottable 0.1.5 prometheus_client NA prompt_toolkit 3.0.52 psutil 7.0.0 pure_eval 0.2.3 pyarrow 22.0.0 pycparser 2.22 pydev_ipython NA pydevconsole NA pydevd 3.2.3 pydevd_file_utils NA pydevd_plugins NA pydevd_tracing NA pydot 4.0.1 pygments 2.19.2 pynndescent 0.5.13 pyparsing 3.2.3 pythonjsonlogger NA pytorch_tabnet NA pytz 2025.2 referencing NA requests 2.32.5 rfc3339_validator 0.1.4 rfc3986_validator 0.1.1 rfc3987_syntax NA rpds NA scipy 1.12.0 seaborn 0.13.2 send2trash NA shap 0.48.0 simplejson 3.20.1 six 1.17.0 skimage 0.25.2 sklearn 1.7.1 skmisc 0.5.1 slicer NA sniffio 1.3.1 sparse 0.17.0 sqlalchemy 2.0.43 stack_data 0.6.3 statsmodels 0.14.5 sympy 1.14.0 texttable 1.7.0 threadpoolctl 3.6.0 tlz 1.0.0 tomli 2.2.1 toolz 1.0.0 torch 2.8.0+cu128 torchgen NA tornado 6.5.2 tqdm 4.64.1 traitlets 5.14.3 triton 3.4.0 typing_extensions NA umap 0.5.9.post2 uri_template NA urllib3 2.5.0 wcwidth 0.2.13 webcolors NA websocket 1.8.0 xarray 2025.6.1 yaml 6.0.2 zipp NA zmq 27.0.2 zoneinfo NA
----- IPython 8.37.0 jupyter_client 8.6.3 jupyter_core 5.8.1 jupyterlab 4.5.1 ----- Python 3.10.18 (main, Jun 5 2025, 13:14:17) [GCC 11.2.0] Linux-6.6.87.2-microsoft-standard-WSL2-x86_64-with-glibc2.35 ----- Session information updated at 2026-01-29 14:49