scAdam predict#
scAdam is specifically developed for annotating cell types, especially focusing on rare cell types that may be underrepresented in the dataset.
Advantages 1. scAdam not only detects all cell types in any test dataset but also generates reproducible results, which is an important aspect for reliable biological interpretation. 2) It enables multitasking by allowing the researchers to extract individual cell types for targeted investigations.
Integration with Other Tools: scAdam is part of a bigger toolkit that includes other tools, such as scEve for surface protein prediction and scNoah for benchmarking, making it a comprehensive solution for single-cell analysis.
[1]:
# Python packages
import warnings
warnings.simplefilter('ignore')
import scanpy as sc
import scparadise
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
sc.set_figure_params(dpi = 120)
Recommendations about dataset#
Our models trained using shifted logarithm normalized data. We recommend shifted logarithm data normalization method to proper usage of our models: sc.pp.normalize_total(adata, target_sum=None) sc.pp.log1p(adata) adata.raw = adata
[2]:
# Load dataset from 10x Genomics
url = "https://cf.10xgenomics.com/samples/cell-exp/6.1.0/10k_PBMC_3p_nextgem_Chromium_X/10k_PBMC_3p_nextgem_Chromium_X_filtered_feature_bc_matrix.h5"
adata = sc.read_10x_h5("dataset.h5", backup_url = url)
adata.var_names_make_unique()
adata
[2]:
AnnData object with n_obs × n_vars = 11996 × 36601
var: 'gene_ids', 'feature_types', 'genome'
QC#
[3]:
# mitochondrial genes, "MT-" for human, "Mt-" for mouse
adata.var["mt"] = adata.var_names.str.startswith("MT-")
# ribosomal genes
adata.var["ribo"] = adata.var_names.str.startswith(("RPS", "RPL"))
# hemoglobin genes
adata.var["hb"] = adata.var_names.str.contains("^HB[^(P)]")
[4]:
sc.pp.calculate_qc_metrics(
adata, qc_vars=["mt", "ribo", "hb"], inplace=True, log1p=True
)
[5]:
sc.pl.violin(
adata,
["n_genes_by_counts", "total_counts", "pct_counts_mt", 'pct_counts_ribo', 'pct_counts_hb'],
jitter=0.4,
multi_panel=True,
)

[6]:
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
[7]:
# Detect doublets
sc.pp.scrublet(adata)
[8]:
# Remove doublets + other QC metrics
adata = adata[adata.obs['predicted_doublet'] == False]
sc.pp.filter_cells(adata, max_genes = 5000)
sc.pp.filter_cells(adata, max_counts = 20000)
adata = adata[adata.obs['pct_counts_mt'] < 15]
Normalization, HVG, neighbors, PCA, UMAP#
We recommend using shifted logarithm data normalization as described here.
[9]:
# Saving count data
adata.layers["counts"] = adata.X.copy()
# Normalization (shifted logarithm)
sc.pp.normalize_total(adata, target_sum=None)
sc.pp.log1p(adata)
# scParadise use normalized data in adata.raw!!!
adata.raw = adata
# HVG
sc.pp.highly_variable_genes(adata, n_top_genes=2000)
# PCA
sc.tl.pca(adata)
# Nearest neighbors analysis
sc.pp.neighbors(adata, n_neighbors=10, n_pcs=20)
# UMAP
sc.tl.umap(adata)
scParadise prediction (scAdam)#
[10]:
# Available models for cell type annotation
df = scparadise.scadam.available_models()
# Show models related to humans
df_human = df[df['Tissue/Model name'].str.startswith('Human_')]
df_human
[10]:
| Tissue/Model name | Description | Suspension | Accuracy | Balanced Accuracy | Number of Levels | |
|---|---|---|---|---|---|---|
| 0 | Human_PBMC | Peripheral blood mononuclear cells of healthy ... | cells | 0.979 | 0.979 | 3 |
| 1 | Human_BMMC | Bone marrow mononuclear cell of healthy adults | cells | 0.947 | 0.942 | 3 |
| 2 | Human_Heart | Human heart CITE-seq analysis of healthy and d... | cells | 0.957 | 0.956 | 2 |
| 3 | Human_Lung | Core Human Lung Cell Atlas | cells | 0.965 | 0.964 | 5 |
| 4 | Human_Lung_Cancer | Extended single-cell lung cancer atlas (LuCA) | cells | 0.937 | 0.936 | 3 |
| 5 | Human_oropharyngeal_SCC | Oropharyngeal HPV+/HPV- squamous cell carcinom... | cells | 0.972 | 0.968 | 2 |
| 6 | Human_Retina | Single cell atlas of the human retina | cells | 0.984 | 0.979 | 4 |
[11]:
# Download model for cell type prediction
scparadise.scadam.download_model('Human_PBMC', save_path='')
[12]:
# Predict cell types using trained model
adata = scparadise.scadam.predict(adata,
path_model = 'Human_PBMC_scAdam/')
Successfully loaded list of genes used for training model
Successfully loaded dictionary of dataset annotations
Successfully loaded model
Successfully added predicted celltype_l1 and cell type probabilities
Successfully added predicted celltype_l2 and cell type probabilities
Successfully added predicted celltype_l3 and cell type probabilities
[13]:
# Visualise predicted cell types levels and prediction probabilities
sc.pl.embedding(adata,
color = [
'pred_celltype_l1',
'prob_celltype_l1',
'pred_celltype_l2',
'prob_celltype_l2',
'pred_celltype_l3',
'prob_celltype_l3'
],
basis = 'X_umap',
frameon = False,
add_outline = True,
legend_loc = 'on data',
legend_fontsize = 7,
legend_fontoutline = 1,
ncols = 2,
wspace = 0,
hspace = 0.1)
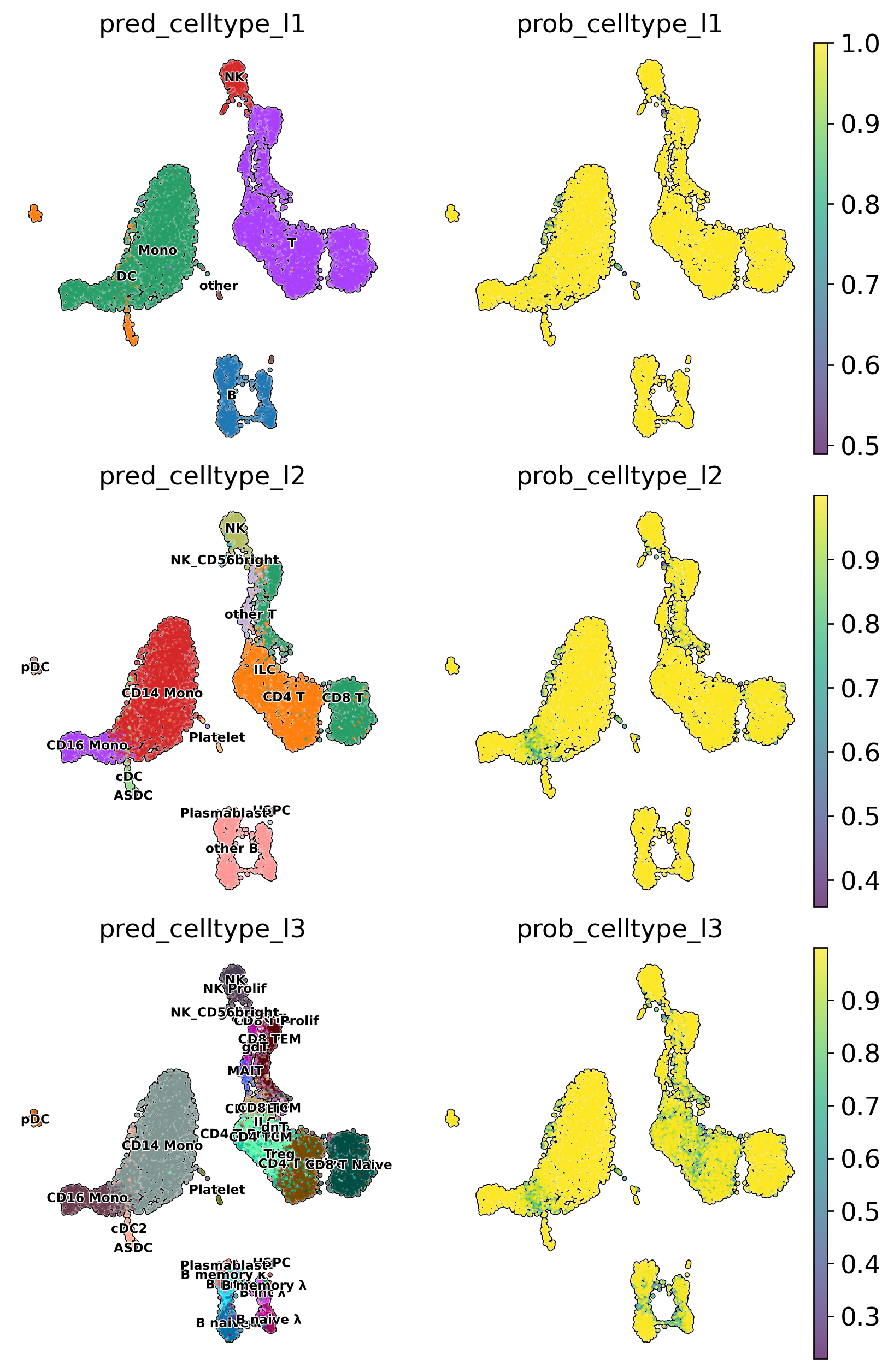
Check prediction results#
[14]:
# Visualization of marker genes of some predicted cell types
marker_genes = {
"CD8 T Naive" : ['CD8B', 'TRABD2A', 'CCR7'],
"CD4 T Naive" : ['CD4', 'TRABD2A', 'CCR7'],
"CD4 TEM": ['CD4', "GZMK", 'CCL5'],
"Treg": ['RTKN2', 'FOXP3', 'IL2RA'],
"B memory": ['SSPN', 'IGHA2', 'AIM2'],
"B naive": ['TCL1A', 'IGHD'],
"NK": ["FCER1G", 'KLRF1'],
"NK_CD56bright": ['GZMK', 'XCL1'],
"CD14 Mono": ['CD14', 'LYZ'],
"CD16 Mono": ['FCGR3A', 'MS4A7'],
"MAIT": ['CXCR6', 'SLC4A10', 'GZMK'],
"Platelet": ['PPBP', 'PF4', 'GP9'],
"pDC": ['SCT', 'CLEC4C', 'IRF8']
}
[15]:
# Make Axes
# Number of needed rows and columns (based on the row with the most columns)
nrow = len(marker_genes)
ncol = max([len(vs) for vs in marker_genes.values()])
fig, axs = plt.subplots(nrow, ncol, figsize=(4 * ncol, 4 * nrow))
# Plot expression for every marker on the corresponding Axes object
for row_idx, (cell_type, markers) in enumerate(marker_genes.items()):
col_idx = 0
for marker in markers:
ax = axs[row_idx, col_idx]
sc.pl.umap(adata, color=marker, ax=ax, show=False, cmap='viridis', frameon=False,
add_outline=True, ncols=3, s=20)
# Add cell type as row label - here we simply add it as ylabel of
# the first Axes object in the row
if col_idx == 0:
# We disabled axis drawing in UMAP to have plots without background and border
# so we need to re-enable axis to plot the ylabel
ax.axis("on")
ax.tick_params(
top="off",
bottom="off",
left="off",
right="off",
labelleft="on",
labelbottom="off",
)
ax.set_ylabel(cell_type + "\n", rotation=90, fontsize=14)
ax.set(frame_on=False)
col_idx += 1
# Remove unused column Axes in the current row
while col_idx < ncol:
axs[row_idx, col_idx].remove()
col_idx += 1
# Alignment within the Figure
fig.tight_layout()
[16]:
# Save anndata with predicted annotations
adata.write_h5ad('adata_predicted.h5ad')
[17]:
import session_info
session_info.show()
[17]:
Click to view session information
----- anndata 0.10.8 matplotlib 3.9.2 numpy 1.25.0 pandas 2.2.3 scanpy 1.10.3 scparadise 0.3.1_beta session_info 1.0.0 -----
Click to view modules imported as dependencies
PIL 10.4.0 anyio NA arrow 1.3.0 asciitree NA asttokens NA attr 24.2.0 attrs 24.2.0 awkward 2.7.1 awkward_cpp NA babel 2.16.0 backports NA certifi 2024.08.30 cffi 1.17.1 charset_normalizer 3.3.2 cloudpickle 3.1.0 colorlog NA comm 0.2.2 cycler 0.12.1 cython_runtime NA dask 2024.8.0 dateutil 2.9.0.post0 debugpy 1.8.6 decorator 5.1.1 defusedxml 0.7.1 exceptiongroup 1.2.2 executing 2.1.0 fastjsonschema NA fqdn NA fsspec 2023.6.0 h5py 3.12.1 idna 3.10 igraph 0.11.6 imblearn 0.12.3 importlib_metadata NA importlib_resources NA ipykernel 6.29.5 isoduration NA jaraco NA jedi 0.19.1 jinja2 3.1.4 joblib 1.4.2 json5 0.9.25 jsonpointer 3.0.0 jsonschema 4.23.0 jsonschema_specifications NA jupyter_events 0.10.0 jupyter_server 2.14.2 jupyterlab_server 2.27.3 kiwisolver 1.4.7 lazy_loader 0.4 legacy_api_wrap NA leidenalg 0.10.2 llvmlite 0.43.0 markupsafe 2.1.5 matplotlib_inline 0.1.7 more_itertools 10.5.0 mpl_toolkits NA msgpack 1.1.0 mudata 0.2.4 muon 0.1.6 natsort 8.4.0 nbformat 5.10.4 numba 0.60.0 numcodecs 0.12.1 optuna 4.0.0 overrides NA packaging 24.1 parso 0.8.4 patsy 0.5.6 pexpect 4.9.0 platformdirs 4.3.6 plotly 5.24.1 pooch v1.8.2 prometheus_client NA prompt_toolkit 3.0.48 psutil 6.0.0 ptyprocess 0.7.0 pure_eval 0.2.3 pyarrow 18.1.0 pycparser 2.22 pydev_ipython NA pydevconsole NA pydevd 3.1.0 pydevd_file_utils NA pydevd_plugins NA pydevd_tracing NA pydot 3.0.3 pygments 2.18.0 pynndescent 0.5.13 pyparsing 3.1.4 pythonjsonlogger NA pytorch_tabnet NA pytz 2024.2 referencing NA requests 2.32.3 rfc3339_validator 0.1.4 rfc3986_validator 0.1.1 rich NA rpds NA scipy 1.13.1 seaborn 0.13.2 send2trash NA setuptools 75.1.0 setuptools_scm NA shap 0.46.0 six 1.16.0 skimage 0.24.0 sklearn 1.5.2 slicer NA sniffio 1.3.1 stack_data 0.6.3 statsmodels 0.14.3 tblib 3.0.0 texttable 1.7.0 threadpoolctl 3.5.0 tlz 0.12.1 tomli 2.0.1 toolz 0.12.1 torch 2.4.1+cu121 torchgen NA tornado 6.4.1 tqdm 4.66.5 traitlets 5.14.3 typing_extensions NA umap 0.5.6 uri_template NA urllib3 1.26.20 wcwidth 0.2.13 webcolors 24.8.0 websocket 1.8.0 yaml 6.0.2 zarr 2.18.2 zipp NA zmq 26.2.0 zoneinfo NA
----- IPython 8.18.1 jupyter_client 8.6.3 jupyter_core 5.7.2 jupyterlab 4.2.5 ----- Python 3.9.19 (main, May 6 2024, 19:43:03) [GCC 11.2.0] Linux-5.15.167.4-microsoft-standard-WSL2-x86_64-with-glibc2.35 ----- Session information updated at 2025-01-15 22:49