Using scEve to improve clustering#
[1]:
# Import libraries
import warnings
warnings.simplefilter('ignore')
import scanpy as sc
import scparadise
import muon as mu
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Recommendations about dataset#
Our models trained using shifted logarithm normalized data. We recommend shifted logarithm data normalization method to proper usage of our models: sc.pp.normalize_total(adata, target_sum=None) sc.pp.log1p(adata) adata.raw = adata
[2]:
# Load example data from 10x Genomics
url = "https://cf.10xgenomics.com/samples/cell-exp/6.0.0/10k_PBMCs_TotalSeq_B_3p/10k_PBMCs_TotalSeq_B_3p_filtered_feature_bc_matrix.h5"
mdata = mu.read_10x_h5("dataset.h5", backup_url = url)
adata_adt = mdata.mod['prot'].copy()
adata = mdata.mod['rna'].copy()
adata.var_names_make_unique()
del mdata
[3]:
# Create/Load AnnData
# adata = sc.read_10x_h5("filtered_feature_bc_matrix.h5")
# adata = sc.read_h5ad('adata.h5ad')
Gene expression data processing#
[4]:
# mitochondrial genes, "MT-" for human, "Mt-" for mouse
adata.var["mt"] = adata.var_names.str.startswith("MT-")
# ribosomal genes
adata.var["ribo"] = adata.var_names.str.startswith(("RPS", "RPL"))
# hemoglobin genes
adata.var["hb"] = adata.var_names.str.contains("^HB[^(P)]")
[5]:
sc.pp.calculate_qc_metrics(
adata, qc_vars=["mt", "ribo", "hb"], inplace=True, log1p=True
)
[6]:
sc.pl.violin(
adata,
["n_genes_by_counts", "total_counts", "pct_counts_mt", 'pct_counts_ribo', 'pct_counts_hb'],
jitter=0.4,
multi_panel=True,
)

[7]:
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
[8]:
# Detect doublets
sc.pp.scrublet(adata)
[9]:
# Remove doublets + other QC metrics
adata = adata[adata.obs['predicted_doublet'] == False]
sc.pp.filter_cells(adata, max_genes = 5000)
adata = adata[adata.obs['pct_counts_mt'] < 20]
Normalization, HVG, neighbors, PCA, UMAP of RNA data#
[10]:
# Saving count data
adata.layers["counts"] = adata.X.copy()
# Normalization
sc.pp.normalize_total(adata, target_sum=None)
sc.pp.log1p(adata)
# scParadise use normalized data in adata.raw!!!
adata.raw = adata
# HVG
sc.pp.highly_variable_genes(adata, n_top_genes=1200)
# PCA
sc.tl.pca(adata)
# Nearest neighbors analysis
sc.pp.neighbors(adata, n_neighbors=10, n_pcs=15)
# UMAP
sc.tl.umap(adata, random_state=1)
# Clusterization
sc.tl.leiden(adata, resolution=0.5, key_added='leiden_0.5')
[11]:
# Visualise clustering
sc.pl.embedding(adata,
color = [
'leiden_0.5'
],
basis = 'X_umap',
frameon = False,
add_outline = True,
legend_loc = 'on data',
legend_fontsize = 10,
legend_fontoutline = 2)
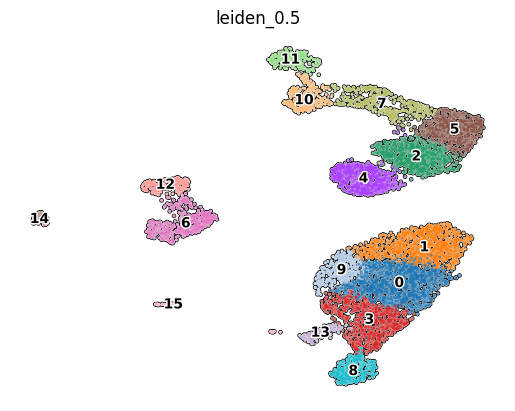
Visualization of NK and T cell scores#
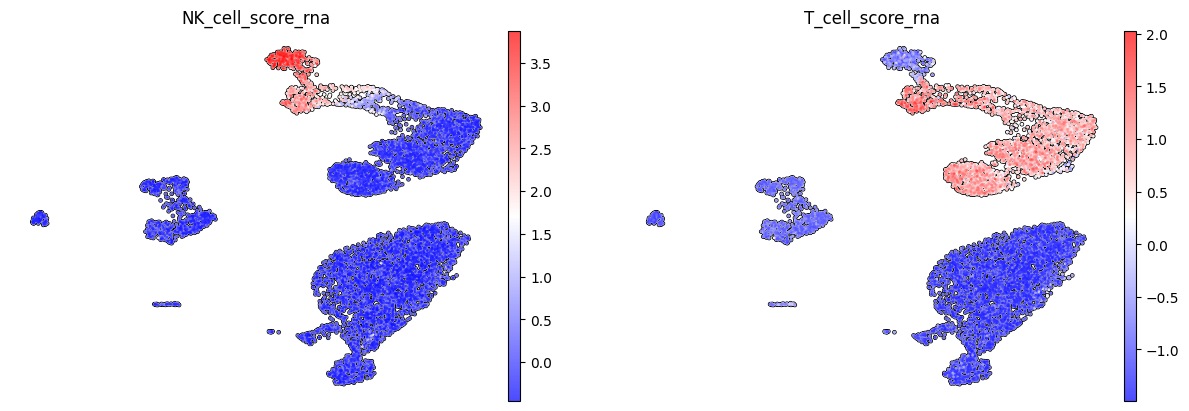
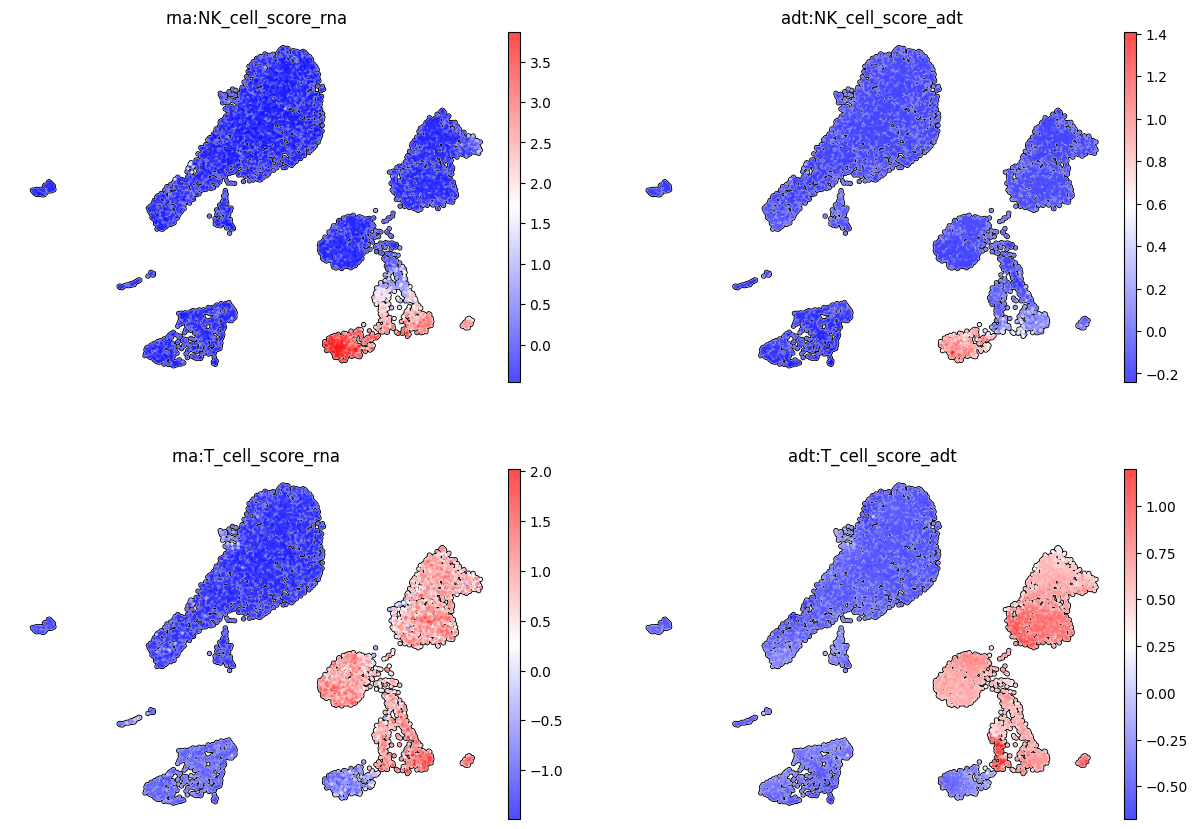
To demonstrate the functionality of the scEve model, we use the classic problem of separating transcriptomically similar NK and T cells (specifically CD8+ cytotoxic T cells). The second classic problem is the separation of CD4+ and CD8+ T cell subtypes (effector and memory cells), as well as other types of T cells. Below are the T and NK scores calculated based on the marker genes of these cell types.
[12]:
# Make NK cell score based on RNA expression
score_1 = 'NK_cell_score_rna'
markers = ['GNLY', 'NKG7', 'KLRF1']
sc.tl.score_genes(adata, markers, score_name=score_1)
# Make T cell score based on RNA expression
score_2 = 'T_cell_score_rna'
markers = ['CD3E', 'CD3G', 'CD3D']
sc.tl.score_genes(adata, markers, score_name=score_2)
# Visualize scores
sc.pl.umap(
adata,
color = [score_1,
score_2
],
cmap = "bwr",
frameon = False,
add_outline = True,
ncols = 2
)
[13]:
# Calculate Integral of absolute density difference and Mutual information
scparadise.scnoah.clust_diff(
adata,
groupby = 'leiden_0.5',
group1 = '11',
group2 = '10',
score1 = 'NK_cell_score_rna',
score2 = 'T_cell_score_rna'
)
[13]:
(47710.846399661226, 0.5454467882345289)
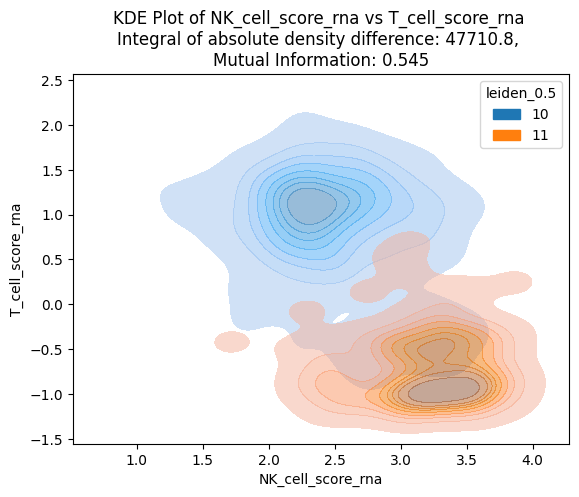
Using RNA data, it is not possible to clearly define the cell type of cluster 10 (they can be either NK cells or T cells).
The KDE plot also shows an overlap between 10 and 11 clusters based on NK and T scores calculated using RNA data.
Observed ADT preprocessing#
[14]:
adata_adt = adata_adt[adata.obs_names]
adata_adt.obsm['X_umap'] = adata.obsm['X_umap']
[15]:
mu.prot.pp.clr(adata_adt)
[16]:
# Visualise CD3 and CD56
# CD3 - T cell marker
# CD56 - NK cell marker
sc.pl.embedding(adata_adt,
color = [
'CD3',
'CD56'
],
basis = 'X_umap',
frameon = False,
add_outline = True,
cmap = 'bwr',
ncols = 2,
vmax = 2.5
)

Using the observed proteins, a clear boundary can be seen between NK cells and T cells.
scParadise prediction (scEve + scAdam)#
To clearly differentiate cell types, you can add a new modality (abundance of surface proteins) using scEve models. You can also use scAdam models to predict cell types.
[17]:
# Available models for cell type annotation
df_eve = scparadise.sceve.available_models()
df_eve
WARNING: RMSE, MASE, MSE are error metrics. Lower error metric value -> Better prediction.
RMSE - Root Mean Squared Error
MSE - Mean Squared Error
MAE - Mean Absolute Error
[17]:
| Tissue/Model name | Description | Suspension | RMSE | MAE | Number of Proteins | |
|---|---|---|---|---|---|---|
| 0 | Human_PBMC_3p | Peripheral blood mononuclear cells of healthy ... | cells | 0.305 | 0.226 | 224 |
| 1 | Human_PBMC_5p | Peripheral blood mononuclear cells of healthy ... | cells | 0.308 | 0.225 | 54 |
| 2 | Human_BMMC | Bone marrow mononuclear cell of healthy adults | cells | 0.706 | 0.454 | 134 |
| 3 | Human_Heart | Human heart CITE-seq analysis of healthy and d... | cells | 0.399 | 0.287 | 270 |
| 4 | Mouse_Spleen_Lymph_node | Spleen and Lymph node immune cells of healthy ... | cells | 0.313 | 0.214 | 113 |
[18]:
# Download model for cell type prediction
scparadise.sceve.download_model(model_name = 'Human_PBMC_3p',
save_path = '')
[19]:
# Predict cell types using trained scEve model
mdata = scparadise.sceve.predict(adata,
path_model = 'Human_PBMC_3p_scEve',
return_mdata = True)
Successfully loaded list of genes used for training model
Successfully loaded list of features used for training model
Successfully loaded model
[20]:
# Available models for cell type annotation
df_adam = scparadise.scadam.available_models()
# Show models related to humans
df_adam_human = df_adam[df_adam['Tissue/Model name'].str.startswith('Human_')]
df_adam_human
[20]:
| Tissue/Model name | Description | Suspension | Accuracy | Balanced Accuracy | Number of Levels | |
|---|---|---|---|---|---|---|
| 0 | Human_PBMC | Peripheral blood mononuclear cells of healthy ... | cells | 0.979 | 0.979 | 3 |
| 1 | Human_BMMC | Bone marrow mononuclear cell of healthy adults | cells | 0.947 | 0.942 | 3 |
| 2 | Human_Heart | Human heart CITE-seq analysis of healthy and d... | cells | 0.957 | 0.956 | 2 |
| 3 | Human_Lung | Core Human Lung Cell Atlas | cells | 0.965 | 0.964 | 5 |
| 4 | Human_Lung_Cancer | Extended single-cell lung cancer atlas (LuCA) | cells | 0.937 | 0.936 | 3 |
| 5 | Human_oropharyngeal_SCC | Oropharyngeal HPV+/HPV- squamous cell carcinom... | cells | 0.972 | 0.968 | 2 |
| 6 | Human_Brain_atlas | Human Brain Cell Atlas v1.0 | nuclei | 0.998 | 0.998 | 2 |
| 7 | Human_Brain_SEA_AD | Seattle Alzheimer’s Disease Brain Cell Atlas | nuclei | 0.997 | 0.997 | 3 |
| 8 | Human_CC_Dev_RNA | Multi-omic profiling of the developing human c... | nuclei | 0.974 | 0.975 | 2 |
| 9 | Human_CC_Dev_ATAC | Multi-omic profiling of the developing human c... | nuclei | 0.916 | 0.912 | 2 |
| 10 | Human_Kidney_cell | scRNA-seq of the Adult Human Kidney (V. 1.5) | cells | 0.974 | 0.974 | 3 |
| 11 | Human_Kidney_nucleus | snRNA-seq of the Adult Human Kidney (V. 1.5) | nuclei | 0.973 | 0.972 | 3 |
| 12 | Human_Retina_cell | Single cell atlas of the human retina | cells | 0.984 | 0.979 | 4 |
| 13 | Human_Retina_nucleus | Single nucleus atlas of the human retina | nuclei | 0.994 | 0.994 | 2 |
[21]:
scparadise.scadam.download_model(model_name = 'Human_PBMC',
save_path = '')
[22]:
mdata.mod['rna'] = scparadise.scadam.predict(mdata.mod['rna'],
path_model = 'Human_PBMC_scAdam')
mdata.update()
Successfully loaded list of genes used for training model
Successfully loaded dictionary of dataset annotations
Successfully loaded model
Successfully added predicted celltype_l1 and cell type probabilities
Successfully added predicted celltype_l2 and cell type probabilities
Successfully added predicted celltype_l3 and cell type probabilities
Clusterization and UMAP using imputed adt (abundance of surface proteins)#
Next, we recommend using only highly correlated proteins for PCA calculation. Among the lowly correlated proteins, there are also antibodies that poorly bound to cells in the training dataset.
[23]:
scparadise.sceve.high_corr(mdata.mod['adt'],
path_model = 'Human_PBMC_3p_scEve',
threshold = 0.6,
subset = False)
[24]:
# PCA using only highly correlated proteins
mdata.mod['adt'].var['highly_variable'] = mdata.mod['adt'].var['highly_correlated']
sc.tl.pca(mdata.mod['adt'], use_highly_variable = True)
[25]:
# Concatenate PCA from rna and imputed adt
mdata.obsm["X_pca_concat"] = np.hstack([mdata.mod["rna"].obsm["X_pca"][:, :15], mdata.mod["adt"].obsm["X_pca"][:, :5]])
mdata.update()
[26]:
# Nearest neighbors analysis
sc.pp.neighbors(mdata, n_neighbors = 10, n_pcs = 20, use_rep = "X_pca_concat")
# UMAP
sc.tl.umap(mdata, random_state = 1)
# Clusterization
sc.tl.leiden(mdata, resolution = 0.5, key_added='leiden_0.5')
[27]:
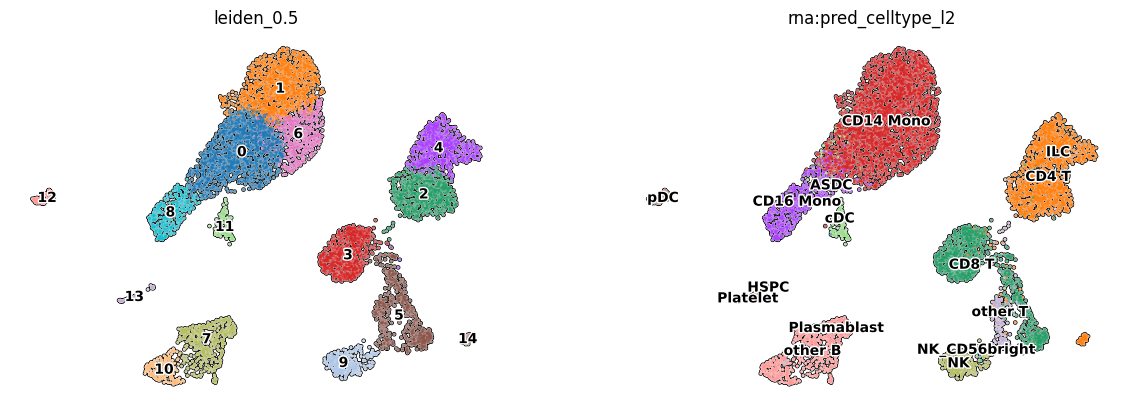
# Visualise clusterization on UMAP calculated using rna and imputed adt PCA
mu.pl.embedding(mdata,
color = [
'leiden_0.5',
'rna:pred_celltype_l2'
],
basis = 'X_umap',
frameon = False,
add_outline = True,
legend_loc = 'on data',
legend_fontsize = 10,
legend_fontoutline = 2
)
[28]:
# Select clusters of T cells
mdata_T_NK = mdata[mdata.obs['leiden_0.5'].isin(['2', '4', '14', '3', '5', '9'])].copy()
[29]:
mu.pl.embedding(mdata_T_NK,
color = [
'rna:pred_celltype_l3'
],
groups = ['CD4 T Naive',
'CD4 TCM',
'CD4 TEM',
'CD4 CTL',
'CD8 T Naive',
'CD8 TCM',
'CD8 TEM',
'Treg',
'MAIT',
'gdT',
'NK'],
basis = 'X_umap',
frameon = False,
add_outline = True,
legend_loc = 'right margin',
legend_fontsize = 10,
legend_fontoutline = 2
)
# NA - some rare cell types (double negative T cells, NK CD56 bright, proliferative T and NK cells)

scEve surface protein prediction allows for a clear separation of T and NK cell subtypes, as seen in the resulting clustering and UMAP.
[30]:
# Make NK cell score based on imputed proteins
score_3 = 'NK_cell_score_adt'
markers = ['adt_CD56-1_pred', 'adt_CD56-2_pred', 'adt_CD158b_pred', 'adt_CD158_pred', 'adt_CD335_pred']
sc.tl.score_genes(mdata.mod['adt'], markers, score_name = score_3)
# Make T cell score based on imputed proteins
score_4 = 'T_cell_score_adt'
markers = ['adt_CD3-1_pred','adt_CD3-2_pred']
sc.tl.score_genes(mdata.mod['adt'], markers, score_name = score_4)
mdata.update()
# Visualize scores
sc.pl.umap(
mdata,
color = ['rna:' + score_1, # RNA based NK score
'adt:' + score_3, # ADT based NK score
'rna:' + score_2, # RNA based T score
'adt:' + score_4 # ADT based T score
],
cmap = "bwr",
frameon = False,
add_outline = True,
s = 20,
ncols = 2
)
[31]:
for i in ['adt', 'rna']:
mdata.obs[f'T_cell_score_{i}'] = mdata.mod['adt'].obs[f'T_cell_score_{i}']
mdata.obs[f'NK_cell_score_{i}'] = mdata.mod['adt'].obs[f'NK_cell_score_{i}']
scparadise.scnoah.clust_diff(
mdata,
groupby = 'leiden_0.5',
group1 = '9',
group2 = '5',
score1 = 'NK_cell_score_adt',
score2 = 'T_cell_score_adt'
)
[31]:
(184877.1423779082, 0.8288763456762659)
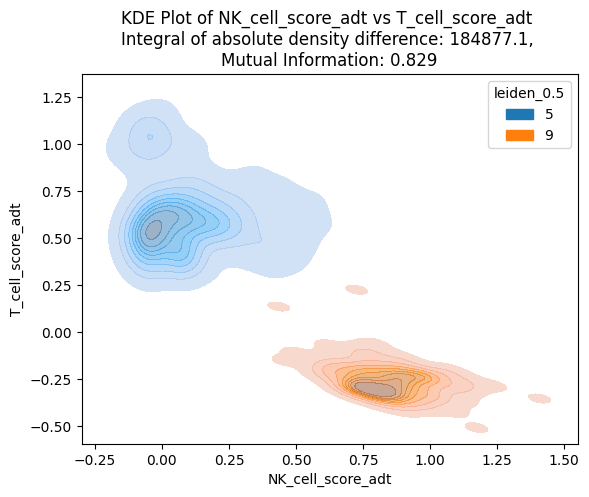
The KDE plot also shows an absence of overlap between 5 and 9 clusters based on NK and T scores calculated using imputed surface protein data.
Integral of absolute density difference increased from 47710 to 184877.
Mutual information increased from 0.545 to 0.829.
Each metric follows the principle that the higher the value, the better the clusters separate the selected scores.
[32]:
# Visualize RNA and ADT markers of T cell subtypes
mu.pl.embedding(mdata,
color = [
'adt_CD8_pred',
'adt_CD8a_pred',
'CD8A',
'CD8B',
'adt_CD4-2_pred',
'adt_CD4-1_pred',
'CD4'
],
basis = 'X_umap',
frameon = False,
add_outline = True,
cmap = 'bwr',
ncols = 4
)

Imputed surface proteins facilitates cell type annotation#
[33]:
# Marker genes
markers_dict = {
"B": ["CD79A", "MS4A1", 'adt_CD19_pred', 'adt_CD20_pred'],
"plasmacytoid DC": ["IRF7", "IRF8", 'adt_CD304_pred', 'adt_CD303_pred'],
"classical DC": ["FCER1A", "adt_CD1c_pred"],
"CD14+ Monocytes": ["CD14", 'adt_CD14_pred'],
"CD16+ Monocytes": ["FCGR3A", 'adt_CD16_pred'],
"NK": ["GNLY", "NKG7", 'adt_CD56-1_pred', 'adt_CD56-2_pred'],
"CD4 T": ["CD4", 'adt_CD4-1_pred', 'adt_CD4-2_pred'],
"CD8 T": ["CD8A", 'CD8B', 'adt_CD8_pred', 'adt_CD8a_pred',],
"Platelet": ["PPBP", 'PF4'],
"HSPC": ['CD34', 'GATA2', 'adt_CD34_pred']
}
[34]:
# Make Axes
# Number of needed rows and columns (based on the row with the most columns)
nrow = len(markers_dict)
ncol = max([len(vs) for vs in markers_dict.values()])
fig, axs = plt.subplots(nrow, ncol, figsize=(4 * ncol, 4 * nrow))
# Plot expression for every marker on the corresponding Axes object
for row_idx, (cell_type, markers) in enumerate(markers_dict.items()):
col_idx = 0
for marker in markers:
ax = axs[row_idx, col_idx]
mu.pl.umap(mdata, color=marker, ax=ax, show=False, frameon=False, s=20)
# Add cell type as row label - here we simply add it as ylabel of
# the first Axes object in the row
if col_idx == 0:
# We disabled axis drawing in UMAP to have plots without background and border
# so we need to re-enable axis to plot the ylabel
ax.axis("on")
ax.tick_params(
top="off",
bottom="off",
left="off",
right="off",
labelleft="on",
labelbottom="off",
)
ax.set_ylabel(cell_type + "\n", rotation=90, fontsize=14)
ax.set(frame_on=False)
col_idx += 1
# Remove unused column Axes in the current row
while col_idx < ncol:
axs[row_idx, col_idx].remove()
col_idx += 1
# Alignment within the Figure
fig.tight_layout()

[35]:
mdata.write_h5mu('pbmc_mdata.h5mu')
[36]:
pip list
Package Version
--------------------------- --------------
absl-py 2.1.0
accelerate 1.4.0
adjustText 1.3.0
aiobotocore 2.5.4
aiohappyeyeballs 2.4.2
aiohttp 3.10.8
aioitertools 0.12.0
aiosignal 1.3.1
airr 1.5.1
alembic 1.13.3
anndata 0.10.8
annoy 1.17.3
anyio 4.6.0
argon2-cffi 23.1.0
argon2-cffi-bindings 21.2.0
array_api_compat 1.8
arrow 1.3.0
asciitree 0.3.3
asttokens 2.4.1
async-lru 2.0.4
async-timeout 4.0.3
attrs 24.2.0
awkward 2.7.1
awkward_cpp 42
babel 2.16.0
bamnostic 1.1.10
bbknn 1.6.0
beautifulsoup4 4.12.3
bleach 6.1.0
botocore 1.31.17
cachetools 4.2.4
certifi 2024.8.30
cffi 1.17.1
charset-normalizer 3.3.2
chex 0.1.86
click 8.1.7
cloudpickle 3.1.0
colorcet 3.1.0
colorlog 6.8.2
comm 0.2.2
contextlib2 21.6.0
contourpy 1.3.0
cycler 0.12.1
Cython 3.0.12
dask 2024.8.0
dask-expr 1.1.10
dask-image 2024.5.3
datashader 0.16.3
debugpy 1.8.6
decorator 5.1.1
decoupler 1.8.0
defusedxml 0.7.1
denoising-diffusion-pytorch 2.1.1
Deprecated 1.2.15
distributed 2024.8.0
docrep 0.3.2
einops 0.8.0
ema-pytorch 0.7.7
episcanpy 0.4.0
etils 1.5.2
exceptiongroup 1.2.2
executing 2.1.0
fasteners 0.19
fastjsonschema 2.20.0
filelock 3.16.1
flax 0.8.5
fonttools 4.54.1
fqdn 1.5.1
frozenlist 1.4.1
fsspec 2023.6.0
geopandas 1.0.1
get-annotations 0.1.2
google-auth 1.35.0
google-auth-oauthlib 0.4.6
greenlet 3.1.1
grpcio 1.70.0
h11 0.14.0
h5py 3.4.0
harmony-pytorch 0.1.8
harmonypy 0.0.10
httpcore 1.0.5
httpx 0.27.2
huggingface-hub 0.29.1
humanize 4.10.0
idna 3.10
igraph 0.11.6
imageio 2.36.1
imbalanced-learn 0.12.3
importlib_metadata 8.5.0
importlib_resources 6.4.5
inflect 7.4.0
intervaltree 3.1.0
ipykernel 6.29.5
ipython 8.18.1
isoduration 20.11.0
jax 0.4.30
jax-cuda12-pjrt 0.4.30
jax-cuda12-plugin 0.4.30
jaxlib 0.4.30
jedi 0.19.1
Jinja2 3.1.4
jmespath 1.0.1
joblib 1.4.2
json5 0.9.25
jsonpointer 3.0.0
jsonschema 4.23.0
jsonschema-specifications 2023.12.1
jupyter_client 8.6.3
jupyter_core 5.7.2
jupyter-events 0.10.0
jupyter-lsp 2.2.5
jupyter_server 2.14.2
jupyter_server_terminals 0.5.3
jupyterlab 4.2.5
jupyterlab_pygments 0.3.0
jupyterlab_server 2.27.3
kiwisolver 1.4.7
kneed 0.8.5
lazy_loader 0.4
legacy-api-wrap 1.4
leidenalg 0.10.2
Levenshtein 0.26.1
lightning 2.4.0
lightning-utilities 0.11.7
llvmlite 0.43.0
locket 1.0.0
louvain 0.8.2
Mako 1.3.5
Markdown 3.7
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.9.2
matplotlib-inline 0.1.7
matplotlib-scalebar 0.8.1
mdurl 0.1.2
mistune 3.0.2
ml_collections 0.1.1
ml_dtypes 0.5.0
more-itertools 10.5.0
mousipy 0.1.6
mpmath 1.3.0
msgpack 1.1.0
mudata 0.2.4
multidict 6.1.0
multipledispatch 1.0.0
multiscale_spatial_image 1.0.1
muon 0.1.6
natsort 8.4.0
nbclient 0.10.0
nbconvert 7.16.4
nbformat 5.10.4
nest-asyncio 1.6.0
networkx 3.2.1
notebook_shim 0.2.4
numba 0.60.0
numcodecs 0.12.1
numpy 1.25.0
numpyro 0.15.3
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvcc-cu12 12.6.68
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 9.1.0.70
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.20.5
nvidia-nvjitlink-cu12 12.6.68
nvidia-nvtx-cu12 12.1.105
oauthlib 3.2.2
ome-zarr 0.9.0
omnipath 1.0.8
opt_einsum 3.4.0
optax 0.2.3
optuna 4.0.0
orbax-checkpoint 0.6.4
overrides 7.7.0
packaging 24.1
pandas 2.2.3
pandocfilters 1.5.1
param 2.1.1
parasail 1.3.4
parso 0.8.4
partd 1.4.2
patsy 0.5.6
pexpect 4.9.0
pillow 10.4.0
PIMS 0.7
pip 24.2
platformdirs 4.3.6
plotly 5.24.1
pooch 1.8.2
prometheus_client 0.21.0
prompt_toolkit 3.0.48
protobuf 3.17.2
psutil 6.0.0
ptyprocess 0.7.0
pure_eval 0.2.3
pyarrow 18.1.0
pyasn1 0.6.1
pyasn1_modules 0.4.1
pycparser 2.22
pyct 0.5.0
pydot 3.0.3
Pygments 2.18.0
pynndescent 0.5.13
pyogrio 0.10.0
pyparsing 3.1.4
pyproj 3.6.1
pyro-api 0.1.2
pyro-ppl 1.9.1
pysam 0.22.1
python-dateutil 2.9.0.post0
python-json-logger 2.0.7
python-Levenshtein 0.26.1
pytorch-fid 0.3.0
pytorch-lightning 2.4.0
pytorch-tabnet 4.1.0
pytz 2024.2
PyYAML 6.0.2
pyzmq 26.2.0
RapidFuzz 3.10.1
referencing 0.35.1
requests 2.32.3
requests-oauthlib 2.0.0
rfc3339-validator 0.1.4
rfc3986-validator 0.1.1
rich 13.8.1
rpds-py 0.20.0
rsa 4.9
s3fs 2023.6.0
safetensors 0.5.2
scanpy 1.10.3
scgen 2.1.0
scib 1.1.6
scikit-image 0.24.0
scikit-learn 1.5.2
scikit-misc 0.3.1
scipy 1.13.1
scirpy 0.17.2
scparadise 0.5.0b0
scvi-tools 1.1.6.post2
seaborn 0.13.2
Send2Trash 1.8.3
session_info 1.0.0
setuptools 75.1.0
setuptools-scm 8.1.0
shap 0.46.0
shapely 2.0.6
six 1.16.0
slicer 0.0.8
slicerator 1.1.0
sniffio 1.3.1
sortedcontainers 2.4.0
soupsieve 2.6
spatial_image 1.1.0
spatialdata 0.2.5.post0
SQLAlchemy 2.0.35
squarify 0.4.4
squidpy 1.6.1
stack-data 0.6.3
statsmodels 0.14.3
stdlib-list 0.10.0
symphonypy 0.2.1
sympy 1.13.3
tbb 2022.0.0
tblib 3.0.0
tcmlib 1.2.0
tenacity 9.0.0
tensorboard 2.6.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
tensorstore 0.1.66
terminado 0.18.1
texttable 1.7.0
threadpoolctl 3.5.0
tifffile 2024.8.30
tinycss2 1.3.0
tomli 2.0.1
toolz 0.12.1
torch 2.4.1+cu121
torchaudio 2.4.1+cu121
torchmetrics 1.4.2
torchvision 0.19.1+cu121
tornado 6.4.1
TOSICA 1.0.0
tqdm 4.66.5
traitlets 5.14.3
triton 3.0.0
typeguard 4.4.1
types-python-dateutil 2.9.0.20240906
typing_extensions 4.12.2
tzdata 2024.2
umap-learn 0.5.6
uri-template 1.3.0
urllib3 1.26.20
validators 0.34.0
wcwidth 0.2.13
webcolors 24.8.0
webencodings 0.5.1
websocket-client 1.8.0
Werkzeug 3.1.3
wget 3.2
wheel 0.44.0
wrapt 1.17.0
xarray 2024.7.0
xarray-dataclasses 1.8.0
xarray-datatree 0.0.15
xarray-schema 0.0.3
xarray-spatial 0.4.0
yamlordereddictloader 0.4.2
yarl 1.13.1
zarr 2.18.2
zict 3.0.0
zipp 3.20.2
Note: you may need to restart the kernel to use updated packages.